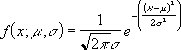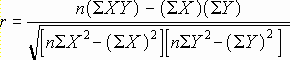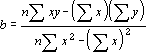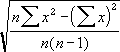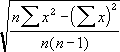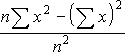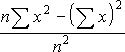(データ全体の平均値に対する個々のデータの絶対偏差の平均を返します)書式 =AVEDEV(数値1, 数値2, ...)
AVEDEV 関数は、データの分散性を測定するときに使用します。
数値1,数値2, ... 絶対偏差の平均を求める数値データを指定します。引数は 1 ? 30 個まで指定できます。引数をカンマ (,) で区切って指定する代わりに、単一配列や、配列への参照を引数として使用することもできます。解説
引数には、数値、あるいは数値を含む名前、配列、またはセル参照を指定します。引数として指定した配列やセル参照に、文字列、論理値、または空白セルが含まれる場合、これらは無視されます。ただし、値が 0 であるセルは、計算の対象となります。
平均絶対偏差は、次の数式で表されます。
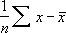
AVEDEV 関数の計算結果は、対象となるデータの計測単位によって変わります。
使用例
AVEDEV(4, 5, 6, 7, 5, 4, 3) = 1.020408
(引数の (数学的な) 平均値を返します)書式 =AVERAGE(数値1, 数値2, ...)
数値1,数値2, ... 平均を求める数値データを指定します。引数は 1~30 個まで指定できます。解説
引数には、数値、あるいは数値を含む名前、配列、またはセル参照を指定します。ヒント
引数として指定した配列やセル参照に、文字列、論理値、または空白セルが含まれる場合、これらは無視されます。
ただし、値が 0 であるセルは、計算の対象となります。
AVERAGE 関数では、空白セルは計算の対象になりませんが、値が 0 であるセルは対象になります。
引数のセル範囲を指定するときは、これらを区別する必要があります。
[オプション] ダイアログ ボックス ([ツール] - [オプション]) の [表示] タブで [ゼロ値] チェック ボックスがオフになっていると、値が 0 であるセルは空白セルと同じように表示されるので、特に注意してください。
使用例
次の例は、セル範囲 A1:A5 が名前 "点数" で定義されている場合です。
A 数値 計算結果 計算式 1 10 =AVERAGE(A1:A5) 2 7 11 =AVERAGE(点数) 3 9 10 =AVERAGE(A1:A5, 5) 4 27 11 =AVERAGE(A1:A5) 5 2 11 = SUM(A1:A5)/COUNT(A1:A5) 次の例は、セル範囲 C1:C3 が名前 "その他の点数" で定義されていて、C1 から順に 4、18、7 という数値が入力されている場合です。
C 数値 計算結果 計算式 1 4 =AVERAGE(点数, その他の点数) 2 18 3 7
(引数リストに含まれる値の (数学的な) 平均値を計算します。数値以外に、文字列や、TRUE、FALSE などの論理値も計算の対象になります)書式 =AVERAGEA(数値1, 数値2,...)
数値1, 数値2,... 平均を求めるセル、セル範囲、または数値データを 1 ? 30 個まで指定します。解説
引数には、数値、名前、配列、またはセル参照を指定します。ヒント
引数として指定した配列またはセル参照に文字列が含まれる場合、これらは 0 (ゼロ) と見なされます。
空白文字列 ("") は、値が 0 (ゼロ) であると見なされます。
計算の対象に文字列の値を含めない場合は、AVERAGE 関数を使用してください。
引数に TRUE が含まれている場合は 1 と見なされ、FALSE が含まれている場合は 0 (ゼロ) と見なされます。
セル範囲の平均を計算する場合は、空白セルと値が 0 であるセルを区別する必要があります。[表示] タブ ([ツール] - [オプション]) の [ゼロ値] チェック ボックスをオフにしていると、特に注意が必要です。空白セルは計算の対象になりませんが、値が 0 であるセルは対象になります。使用例
次の例は、セル範囲 A1:A5 が名前 "点数" で定義されている場合です。
A 数値 計算結果 計算式 1 10 =AVERAGEA(A1:A5) 2 7 5.6 =AVERAGEA(点数) 3 9 5.6 =AVERAGEA(A1:A5) 4 2 5.6 =SUM(A1:A5)/COUNT(A1:A5) 5 無効 11
A 数値 計算結果 計算式 1 10 =AVERAGEA(A1:A5) 2 7 3 9 4 2 5
範囲内の条件に一致するすべてのセルの平均値 (算術平均) を返します。
書式
AVERAGEIF(範囲,条件,平均対象範囲)
範囲 平均する 1 つまたは複数のセル (数値、数値配列、または数値を含む範囲を参照する名前かセル参照など) を指定します。
条件 平均する対象となるセルを定義する条件を数値、式、セル参照、または文字列で指定します。たとえば、条件は 32、"32"、">32"、"Windows"、または B4 のようになります (式および文字列を指定する場合は半角の二重引用符 (") で囲む必要があります)。
平均対象範囲 平均する実際のセルを指定します。何も指定しないと、範囲が使用されます。
解説
| 範囲の指定 | 平均対象範囲の指定 | 評価される実際のセル |
|---|---|---|
| A1:A5 | B1:B5 | B1:B5 |
| A1:A5 | B1:B3 | B1:B5 |
| A1:B4 | C1:D4 | C1:D4 |
| A1:B4 | C1:C2 | C1:D4 |
メモ AVERAGEIF 関数では、データの中心傾向 (統計的分布における数値グループの中心位置) が評価されます。中心傾向を表す指標としては、主に、次の 3 つが挙げられます。
対称分布の場合、中心傾向を表す 3 つの指標はすべて等しい値になります。非対象分布であった場合、3 つの指標はそれぞれ異なる場合があります。
使用例: エアコンの価格と手数料の平均値を求めます。
使用例を新規のワークシートにコピーすると、計算結果を確認できます。
その方法は?
メモ 行見出しまたは列見出しは選択しないでください。

|
|
使用例: 支社の利益の平均値を求めます。
使用例を新規のワークシートにコピーすると、計算結果を確認できます。
その方法は?
メモ 行見出しまたは列見出しは選択しないでください。
|
|
複数の検索条件に一致するすべてのセルの平均値 (算術平均) を返します。
書式
AVERAGEIFS(平均範囲,検索条件範囲 1,検索条件 1,検索条件範囲 2,検索条件 2...)
平均範囲 平均する 1 つまたは複数のセル (数値、数値配列、または数値を含む範囲を参照する名前かセル参照など) を指定します。
条件範囲 1,条件範囲 2, ... 対応する条件による評価の対象となる 1 ~ 127 個の範囲を指定します。
条件 1,条件 2, ... 平均の対象となるセルを定義する 1 ~ 127 個の条件を数値、式、セル参照、または文字列で指定します。たとえば、検索条件は 32、"32"、">32"、"Windows"、または B4 のようになります (式および文字列を指定する場合は半角の二重引用符 (") で囲む必要があります)。
解説
メモ AVERAGEIFS 関数では、データの中心傾向 (統計的分布における数値グループの中心位置) が評価されます。中心傾向を表す指標としては、主に、次の 3 つが挙げられます。
対称分布の場合、中心傾向を表す 3 つの指標はすべて等しい値になります。非対象分布であった場合、3 つの指標はそれぞれ異なる場合があります。
使用例: 学生の成績の平均を求めます。
使用例を新規のワークシートにコピーすると、計算結果を確認できます。
その方法は?
メモ 行見出しまたは列見出しは選択しないでください。
|
|
使用例: 不動産価格の平均を求めます。
使用例を新規のワークシートにコピーすると、計算結果を確認できます。
その方法は?
メモ 行見出しまたは列見出しは選択しないでください。
|
|
(累積β確率密度関数を返します)書式 =BETADIST(x, α, β, A, B)累積β確率密度関数は、複数の標本を対象に割合の変化を分析する場合などに使用します。
たとえば、複数の人が 1 日のうちにテレビを見ている時間の割合を算出するときは、この関数を使用します。
x 区間 A ? B の範囲で、関数を使用して評価する瞬間を指定します。解説
α 確率分布に対するパラメータを指定します。
β 確率分布に対するパラメータを指定します。
A x の区間の下限を指定します。この引数は省略することができます。
B x の区間の上限を指定します。この引数は省略することができます。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例
α 0 または β 0 である場合、エラー値 #NUM! が返されます。
x < A、x > B、または A = B である場合、エラー値 #NUM! が返されます。
A および B を省略すると、標準累積β分布が使用され、A = 0 および B = 1 として計算が行われます。
BETADIST(2,8,10,1,3) = 0.685470581
(累積β確率密度関数の逆関数を返します)つまり、確率 = BETADIST(x,...) であるとき、BETAINV(確率,...) = x という関係が成り立ちます。
累積β確率分布は、プロジェクトの立案時に、予測される完成日数と公差によって、完了可能日時を計算するために使用できます。
書式 =BETAINV(確率, α, β, A, B)
確率 β確率分布に伴う確率を指定します。解説
α 確率分布のパラメータを指定します。
β 確率分布のパラメータを指定します。
A x の区間の下限を指定します。この引数は省略することができます。
B x の区間の上限を指定します。この引数は省略することができます。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例
α 0 または β 0 である場合、エラー値 #NUM! が返されます。
確率 0 または 確率 > 1 である場合、エラー値 #NUM! が返されます。
A および B を省略すると、標準累積β分布が使用され、A = 0 および B = 1 として計算が行われます。
BETAINV 関数の計算には、反復計算の手法が使用されます。確率 の値が指定されると、計算結果の精度が ±3x10-7 以内になるまで反復計算が行われます。反復計算を 100 回行っても結果が収束しない場合は、エラー値 #N/A が返されます。
BETAINV(0.685470581,8,10,1,3) = 2
(個別項の二項分布の確率を返します)この関数は、一定の回数の試行を伴う問題で次のような場合に利用します。
試行の結果が成功または失敗のいずれかである
試行が独立したものである
実験を通して成功の確率が一定である
たとえば、次に生まれる 3 人の赤ちゃんの中で 2 人が男の子である確率を計算することができます。
書式 =BINOMDIST(成功数, 試行回数, 成功率, 関数形式)
成功数 試行回数 に含まれる成功の回数を指定します。解説
試行回数 独立試行の回数を指定します。
成功率 1 回の試行が成功する確率を指定します。
関数形式 関数の形式を、論理値で指定します。関数形式 に TRUE を指定した場合、BINOMDIST 関数の戻り値は累積分布関数となり、多いときで 成功数 回の成功が得られる確率が計算されます。FALSE の場合は、確率密度関数となり、成功数 回の成功が得られる確率が計算されます。
成功数、試行回数 に整数以外の値を指定すると、小数点以下が切り捨てられます。使用例
成功数、試行回数、成功率 に数値以外の値を指定すると、エラー値 #VALUE! が返されます。
成功数 < 0 または 成功数 > 試行回数 である場合、エラー値 #NUM! が返されます。
成功率 < 0 または 成功率 > 1 である場合、エラー値 #NUM! が返されます。
二項確率密度関数は、次の数式で表されます。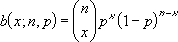
ここで
は COMBIN(n,x) を表します。
二項累積分布関数は、次の数式で表されます。
コインを投げた結果は、表が出るか、裏が出るかのいずれかになります。コインを 1 回投げて表が出る確率は 0.5 ですが、10 回投げて表が 6 回出る確率は、次の数式で計算することができます。
BINOMDIST(6,10,0.5,FALSE) = 0.205078
(片側カイ 2 乗 (χ2) 分布の確率を返します。)書式 =CHIDIST(x, 自由度)χ2 分布は χ2 検定と関連しています。χ2 検定は、実測値と期待値を比較するときに使用します。
たとえば、ある植物の遺伝子実験で、次の世代の花には一定の色の組み合わせが発生するという仮説を立てたとします。
ここで、予測された色と観察の結果を比較することにより、仮説の妥当性を検定することができます。
x 分布を評価する値を指定します。解説
自由度 自由度を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例
x に負の数を指定すると、エラー値 #NUM! が返されます。
自由度 に整数以外の値を指定すると、小数点以下が切り捨てられます。
自由度 < 1 または 自由度 1010 である場合、エラー値 #NUM! が返されます。
CHIDIST 関数は、数式 CHIDIST = P(X>x) で表されます (X = χ2 確率変数)。
CHIDIST(18.307,10) = 0.050001
(カイ 2 乗 (χ2) 分布の逆関数を返します)書式 =CHIINV(確率 自由度)つまり、確率 = CHIDIST(x,...) であるとき、CHIINV(確率,...) = x という関係が成り立ちます。
χ2 検定は、実測値と期待値を比較して、仮説の妥当性を検定するために使います。
確率 χ2 分布に伴う確率を指定します。解説
自由度 自由度を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例
確率 < 0 または 確率 > 1 である場合、エラー値 #NUM! が返されます。
自由度 に整数以外の値を指定すると、小数点以下が切り捨てられます。
自由度 < 1 または 自由度 1010 である場合、エラー値 #NUM! が返されます。CHIINV 関数の計算には、反復計算の手法が使用されます。
確率 の値が指定されると、計算結果の精度が ±3x10-7 以内になるまで反復計算が行われます。
反復計算を 100 回行っても結果が収束しない場合は、エラー値 #N/A が返されます。
CHIINV(0.05,10) = 18.30703
(カイ 2 乗 (χ2) 検定を行います)書式 =CHITEST(実測値範囲, 期待値範囲)CHITEST 関数では、統計と自由度に対する χ2 分布から値を抽出して返します。χ2 検定を行うことにより、仮説が実験によって証明されたかどうかを判断することができます。
実測値範囲 期待値に対する検定の実測値が入力されているデータ範囲を指定します。解説
期待値範囲 期待値が入力されているデータ範囲を指定します。実測値と期待値では、行方向の値の合計と列方向の値の合計がそれぞれ等しくなっている必要があります。
実測値範囲 と 期待値範囲 に含まれるデータの個数が異なる場合、エラー値 #N/A が返されます。使用例
χ2 検定では、まず χ2 統計量が計算され、次に実測値と期待値の差が加算されます。CHITEST 関数は、等式 CHITEST = p(X>χ2) で表されます。ここで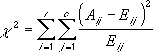
また
Aij = i 行 j 列内の実測値の度数 (実測値頻度)
Eij = i 行 j 列内の期待値の度数 (期待値頻度)
r = 行数
c = 列数
CHITEST 関数では、χ2 統計量と自由度 df に対する確率が計算されます。このとき、df = (r-1)(c-1) となります。
上のデータに対する χ2 統計量は 16.16957 で、自由度は 2 です。
A B C 1 結果 2 男性 女性 3 賛成 58 35 4 中立 11 25 5 反対 10 23 6 7 予想 8 男性 女性 9 賛成 45.35 47.65 10 中立 17.56 18.44 11 反対 16.09 16.91
CHITEST(B3:C5,B9:C11) = 0.000308
(母集団に対する信頼区間を返します)書式 =CONFIDENCE(α, 標準偏差, 標本数)信頼区間とは、標本平均の両側のある範囲のことです。たとえば、通信販売で商品を注文したときに、ある程度の確信を持って、その商品が最も早く到着する日と、最も遅く到着する日を予測することができます。
α 信頼度を計算するために使用する有意水準を指定します。信頼度は 100 * (1-α)% で計算されます。つまり、α = 0.05 であるとき、信頼度は 95% になります。解説標準偏差, データ範囲に対する母集団の標準偏差を指定します。これは、既知であると仮定されます。
標本数 標本数を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例
α 0 または α 1 である場合、エラー値 #NUM! が返されます。
標準偏差, 0 である場合、エラー値 #NUM! が返されます。
標本数 に整数以外の値を指定すると、小数点以下が切り捨てられます。
標本数 < 1 である場合、エラー値 #NUM! が返されます。α = 0.05 と仮定した場合、標準正規分布曲線より下の領域で、全体の (1-α)% つまり 95% の範囲を計算する必要があります。この値は ±1.96 となります。その結果、信頼区間は次の数式で表されます。
郊外に住む会社員 50 人を標本として、通勤時間を調査したところ、片道の平均時間が 30 分で、母集団の標準偏差は 2.5 になりました。母集団の平均に対する信頼区間が次の数式で表されるとき、その信頼度は 95% になります。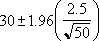
または
CONFIDENCE(0.05,2.5,50) = 0.692951
= 30 ± 0.692951 分
= 29.3 ? 30.7 分
(2つの配列データの相関係数を返します)書式 =CORREL(配列1, 配列2)相関係数は、2 つの特性の関係を判断するときに使用します。たとえば、各地域の平均気温とエアコンの普及率の相関関数を調べることができます。
配列1 データが入力されたセル範囲を指定します。解説
配列2 もう一方のデータが入力されたセル範囲を指定します。
引数には、数値、あるいは数値を含む名前、配列、またはセル参照を指定します。使用例
引数として指定した配列またはセル参照に文字列、論理値、または空白セルが含まれる場合、これらは無視されます。ただし、値が 0 であるセルは、計算の対象となります。
配列1 と 配列2 に含まれるデータの個数が異なる場合、エラー値 #N/A が返されます。
配列1 または 配列2 が空白である場合、または双方のデータの s (標準偏差) が 0 になる場合、エラー値 #DIV/0! が返されます。
相関関数は次の数式で計算できます。
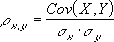
ここで
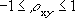
また
CORREL({3,2,4,5,6},{9,7,12,15,17}) = 0.997054
(引数リストの各項目に含まれる数値の個数の合計を返します)書式 =COUNT(値1, 値2, ...)引数リストの各項目には、数値、名前、配列、またはセル参照を指定できます。項目にセル参照を指定すると、その範囲内で数値が入力されているセルの個数を調べることができます。
値1, 値2, ... 任意のデータ型を使用し、任意の値、あるいは値を含む名前、配列、またはセル参照を指定します。引数は 1 ? 30 個まで指定できます。ただし、計算の対象となるのは数値だけです。使用例COUNT 関数では、数値、Null (値がないこと)、論理値、日付、数値を表す文字列が計算の対象となります。エラー値、数値に変換できない文字列は無視されます。
引数が配列またはセル参照である場合は、その中に含まれる数値だけが計算の対象となり、空白セル、論理値、文字列、エラー値は無視されます。論理値、文字列、またはエラー値の個数を調べるには、COUNTA 関数を使用します。
次に例を示します。
A 1 売上高 2 1997/2/8 3 4 19 5 22.24 6 TRUE 7 #DIV/0! COUNT(A1:A7) = 3
COUNT(A4:A7) = 2
COUNT(A1:A7, 2) = 4
(引数リストの各項目に含まれるデータの個数の合計を返します)書式 =COUNTA(値1, 値2, ...)引数リストの各項目には、値、名前、配列、またはセル参照を指定できます。項目にセル参照を指定すると、その範囲内でデータが入力されているセルの個数を調べることができます。ただし、セル参照に空白セルが含まれる場合は、その空白セルは個数には数えられません。
値1, 値2, ... 値、あるいは値を含む名前、配列、またはセル参照を指定します。引数は 1 ? 30 個まで指定できます。COUNTA 関数では、空白文字列 ("") を含め、すべてのデータ型の値が計算の対象となります。ただし、空白セルだけは計算の対象となりません。また、引数が配列またはセル参照である場合、その中に含まれる空白セルは無視されます。論理値、文字列、またはエラー値を計算する必要がない場合は、COUNT 関数を使用します。使用例
次に例を示します。
A 1 売上高 2 1997/2/8 3 4 19 5 22.24 6 TRUE 7 #DIV/0! COUNTA(A1:A7) = 6
COUNTA(A4:A7) = 4
COUNTA(A1:A7, 2) = 7
COUNTA(A1:A7, "二") = 7
指定された範囲に含まれる空白セルの個数を返します。
書式
COUNTBLANK(範囲)
範囲 空白セルの個数を求めるセル範囲を指定します。
解説
空白文字列 ("") を返す数式が入力されているセルも計算の対象となります。ただし、数値の 0 を含むセルは計算の対象となりません。
使用例
使用例を新規のワークシートにコピーすると、計算結果を確認できます。
その方法は?
メモ 行見出しまたは列見出しは選択しないでください。
|
|
(指定された範囲に含まれるセルのうち、検索条件に一致するセルの個数を返します)書式 =COUNTIF(範囲, 検索条件)
範囲解説セルの個数を求めるセル範囲を指定します。検索条件計算の対象となるセルを定義する条件を、数値、式、または文字列で指定します。
式および文字列を指定する場合は、">32"、"Windows" のように、半角のダブル クォーテーション (") で囲む必要があります。
Excel には、条件を基にデータを解析できる他の関数があります。使用例
たとえば、文字列または数値の範囲で指定した条件を満たすときに合計を計算するには、SUMIF ワークシート関数を使用します。
特定の売上高に達した場合にボーナスを支給するなど、2 つの値のうち 1 つを返すには、IF ワークシート関数を使用します。
条件に基づいて値を計算する方法については、ここをクリックしてください。
A 計算結果 計算式 3 リンゴ 2 COUNTIF(A3:A6,"リンゴ") 4 オレンジ 5 バナナ 6 リンゴ
B 計算結果 計算式 3 32 2 COUNTIF(B3:B6,">55) 4 54 5 75 6 86
この記事では、Microsoft Office Excel における COUNTIFS 関数の数式構文および使用方法について説明します。
複数の範囲のセルに条件を適用し、すべての条件に一致した回数を返します。
COUNTIFS(条件範囲 1, 検索条件 1, [条件範囲 2, 検索条件 2]…)
COUNTIFS 関数の構文では、以下の引数が使用されます。
重要 各追加範囲の列数と行数は "条件範囲 1" 引数と同じである必要があります。範囲どうしは隣接していなくてもかまいません。
使用例を新規のワークシートにコピーすると、計算結果を確認できます。
その方法は?
重要 行見出しまたは列見出しは選択しないでください。

重要 使用例が正常に動作するためには、ワークシートのセル A1 に貼り付ける必要があります。
使用例は、空のワークシートにコピーした後、ニーズに合わせて変更できます。
|
|
使用例を新規のワークシートにコピーすると、計算結果を確認できます。
その方法は?
重要 行見出しまたは列見出しは選択しないでください。
重要 使用例が正常に動作するためには、ワークシートのセル A1 に貼り付ける必要があります。
使用例は、空のワークシートにコピーした後、ニーズに合わせて変更できます。
|
|
概要
SUMIF ワークシート関数と COUNTIF ワークシート関数
IF ワークシート関数
条件付き合計式 ウィザード
概要
Excel の数式は、ワークシートの値を計算します。
通常、数式は指定範囲内にあるすべての値を計算しますが、指定した検索条件が TRUE (真) のときに数式を変更したり、または検索条件にあてはまる値だけを計算する必要が出てくるときがあります。
たとえば、販売員の受注履歴を管理し、データ構成を変更しないで販売員ごとの売上高を集計したり、または、請求書の総額に基づいて、売上高ごとに支給する特別賞与額を決定する場合などです。
数式が条件を満たしているかどうかをテストする場合、条件付きの数式を Excel で実行できます。
A B 1 販売員 売上高合計 2 吉田 1,5000,000 3 吉田 900,000 4 須山 800,000 5 川本 2,000,000 6 川本 800,000 7 吉田 2,250,000 8 吉田 500,000 9 吉田 1,500,000 10 吉田 500,000 これは販売員ごとの売上高リストです。販売員ごとに特別賞与の歩合を計算し、一定期間中の受注数と売上高合計を集計する場合に、条件付き数式を使用します。
Excel には、検索条件に基づいて結果を算出する 3 つのワークシート関数があります。
指定したセル範囲で検索条件に一致するセルの個数を求める場合、COUNTIF ワークシート関数を使用します。
1 つの検索条件に基づいて合計を計算する場合は、SUMIF ワークシート関数を使用します。
また、2 つの値の一方を返す場合、特別賞与の歩合額など、IF ワークシート関数を使用します。
ワークシート関数を初めてお使いになる場合は、条件付き合計式 ウィザードを使用すると、検索条件に基づいて合計を算出する数式を簡単に作成できます。
たとえば、販売員ごとに、一定期間中の受注合計と売上高合計を表示した概要を作成するとします。
この場合受注合計を求めるには、COUNTIF ワークシート関数を使用します。
また、売上高合計を求めるには、SUMIF ワークシート関数を使用します。
COUNTIF ワークシート関数は、販売員ごとの受注数を計算します。
A B 1 販売員 売上高合計 2 吉田 1,5000,000 3 吉田 900,000 4 須山 800,000 5 川本 2,000,000 6 川本 800,000 7 吉田 2,250,000 8 吉田 500,000 9 吉田 1,500,000 10 吉田 500,000 COUNTIF には、検索対象範囲と範囲内で検索する値 (検索条件) の 2 つの引数があります。
A B 31 販売員 販売数 32 吉田 =COUNTIF(A2:A26,A32) 33 吉田 7 34 須山 5 =COUNTIF(範囲,検索条件)
吉田の場合、次のような関数 (セル B32) になります。
=COUNTIF(A2:A26,A32)
この関数は、販売員リスト (A2 から A26 の範囲) 内に、セル A32 (検索条件) の名前がいくつあるのかを計算します。
SUMIF ワークシート関数は、販売員ごとの売上高合計を計算します。
A B 1 販売員 売上高合計 2 吉田 1,5000,000 3 吉田 900,000 4 須山 800,000 5 川本 2,000,000 6 川本 800,000 7 吉田 2,250,000 8 吉田 500,000 9 吉田 1,500,000 10 吉田 500,000
A B C 31 販売員 販売数 売上高合計 32 吉田 13 =SUMIF(A2:A26,A32,B2:B26) 33 吉田 7 1,500,000 34 須山 5 900,000 SUMIF ワークシート関数は、範囲内の値を検索した後、別の範囲で該当するすべての値を合計します。
SUMIF には、検索対象範囲、範囲内で検索する値 (検索条件)、合計する値を含む範囲の 3 つの引数があります。=SUMIF(範囲,検索条件,合計範囲)
吉田の場合、次のような関数 (セル C32) になります。
=SUMIF(A2:A26,A32,B2:B26)
この場合、販売員リスト (A2 から A26 の範囲) 内から、セル A32 の文字列 (検索条件) を検索し、売上高合計 (B2 から B26 の合計範囲) から該当額を合計します。
たとえば、社内で売上高に応じて、10 % または 15 % の特別賞与をスライド制で決定するとします。条件付き合計式 ウィザード
TRUE (真) または FALSE (偽) の条件に基づいて、この 2 つの値のどちらを適用するのか決定するには、IF ワークシート関数を使用します。
C4 ▼ |= =IF(B4<10000,10%,15%) A B C 1 販売員 売上高合計 ボーナス 2 吉田 1,500,000 15% 3 吉田 900,000 10% 4 須山 800,000 10% 5 須山 2,000,000 15% IF ワークシート関数は、売上高に基づいて 10 % または 15 % のいずれかの特別賞与を返します。
IF ワークシート関数は、TRUE (真) または FALSE (偽) となる条件をテストします。
条件が TRUE (真) のときに、関数は一方の値を返し、FALSE (偽) のときは、もう一方の値を返します。
IF には、テストする条件、条件が TRUE (真) のときに返す値、条件が FALSE (偽) のときに返す値の 3 つの引数があります。=IF(論理式,真の場合,偽の場合)
須山の 8,000 ドルの売上の場合、次のような関数 (セル C4) になります。
=IF(B4<10000,10%,15%)
売上高が 10,000 ドル (論理式) に満たない場合、特別賞与は 10 % (真の場合) になります。
売上高が 10,000 ドル以上の場合は、特別賞与は 15 % (偽の場合) になります。
テストしたい条件が複数ある場合、条件付き合計式 ウィザードを使用すると、条件付き数式を簡単に作成できます。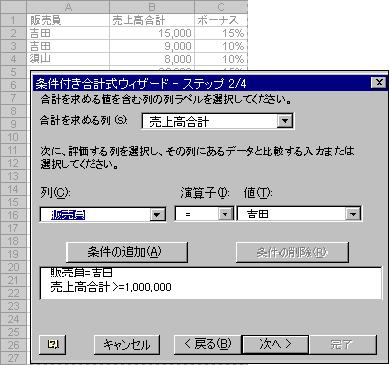
条件付き合計式 ウィザードは、複数の条件を含んだ数式の作成を迅速に行います。
マウスで条件を定義すると、ウィザードがワークシートに数式を追加してくれます。ウィザードでは、リストの場所、テストする条件、テスト結果の場所を指定します。
上記の例では、10,000 ドルを超える吉田の売上高を合計しています。さらにウィザードは、結果を計算する配列数式を作成します。
条件を変更する必要がある場合、ウィザードを使用して、最初に指定した場所の結果を置き換えることができます。
条件付き合計式 ウィザードは、Excel に組み込まれたアドイン プログラムです。
(共分散を返します)書式 =COVAR(配列1, 配列2)
共分散とは、2 組の対応するデータ間での標準偏差の積の平均値です。共分散を利用することによって、2 組のデータの相関関係を分析することができます。たとえば、ある社会集団を対象に、収入と最終学歴の相関関係を調べることができます。
解説
配列1 整数のデータが入力されている一方のセル範囲を指定します。配列2 整数のデータが入力されているもう一方のセル範囲を指定します。
引数には、数値、あるいは数値を含む名前、配列、またはセル参照を指定します。使用例引数として指定された配列またはセル参照に文字列、論理値、または空白セルが含まれる場合、これらは無視されます。ただし、値が 0 であるセルは、計算の対象となります。
配列1 と 配列2 に入力されているデータ数が異なる場合、エラー値 #N/A が返されます。
配列1 または 配列2 にデータが入力されていない場合、エラー値 #DIV/0! が返されます。
共分散は、次の数式で表されます。
COVAR({3, 2, 4, 5, 6}, {9, 7, 12, 15, 17}) = 5.2
(累積二項分布の値が基準値以上になるような最小の値を返します)書式この関数は、品質保証計算などに使用します。たとえば、部品の組立ラインで、ロット全体で許容できる欠陥部品数の最大値を決定することができます。
CRITBINOM(試行回数, 成功率, α)解説試行回数 ベルヌーイ試行の回数を指定します。
成功率 1 回の試行が成功する確率を指定します。
α 基準値を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例試行回数 に整数以外の値を指定すると、小数点以下が切り捨てられます。
試行回数 < 0 である場合、エラー値 #NUM! が返されます。
成功率 <= 0 または 成功率 >= 1である場合、エラー値 #NUM! が返されます。
α < 0 または α > 1である場合、エラー値 #NUM! が返されます。
CRITBINOM(6,0.5,0.75) = 4
(標本の平均値に対する各データの偏差の平方和を返します)書式 =DEVSQ(数値1, 数値2, ...)
数値1,数値2,... 偏差の平方和を求める数値を指定します。引数は 1 ? 30 個まで指定できます。引数をカンマ (,) で区切って指定する代わりに、単一配列や、配列への参照を引数として使用することもできます。解説
引数には、数値、あるいは数値を含む名前、配列、またはセル参照を指定します。使用例引数として指定した配列またはセル参照に、文字列、論理値、または空白セルが含まれる場合、これらは無視されます。ただし、値が 0 であるセルは、計算の対象となります。
偏差の平方和は、次の数式で表されます。
DEVSQ(4,5,8,7,11,4,3) = 48
(指数分布関数を返します)この関数は、銀行の ATM で現金を引き出すのにかかる時間など、イベントの間隔をモデル化する場合に使用します。たとえば、EXPONDIST 関数を使って、ある処理が 1 分以内に終了する確率を算出することができます。
書式 =EXPONDIST(x, λ, 関数形式)
x 関数に代入する値を指定します。λ パラメータの値を指定します。
関数形式 計算に使用する指数関数の形式を論理値で指定します。関数形式 が TRUE の場合、戻り値は累積分布関数となり、FALSE の場合は、確率密度関数が返されます。
解説
x または λ に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例x < 0 である場合、エラー値 #NUM! が返されます。
λ 0 である場合、エラー値 #NUM! が返されます。
確率密度関数は、次の数式で表されます。
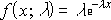
累積分布関数は、次の数式で表されます。
EXPONDIST(0.2,10,TRUE) = 0.864665EXPONDIST(0.2,10,FALSE) = 1.353353
(F 確率分布を返します)書式 =FDIST(x, 自由度1, 自由度2)この関数を使用すると、2 組のデータを比較して、ばらつきが両者で異なるかどうかを調べることができます。たとえば、テストの成績を男女別に分析して、男子生徒の成績と女子生徒の成績のばらつきが異なるかどうかを検定することができます。
x 関数に代入する値を指定します。解説自由度1 自由度の分子を指定します。
自由度2 自由度の分母を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例x < 0 である場合、エラー値 #NUM! が返されます。
自由度1、自由度2 に整数以外の値を指定すると、小数点以下が切り捨てられます。
自由度1 < 1 または 自由度1 1010 である場合、エラー値 #NUM! が返されます。
自由度2 < 1 または 自由度2 1010 である場合、エラー値 #NUM! が返されます。
FDIST 関数は、数式 FDIST=P(F<x) で表されます (F は F 確率分布を持つ任意の変数)。
FDIST(15.20675,6,4) = 0.01
(F 確率分布の逆関数を返します)書式 =FINV(確率, 自由度1, 自由度2)つまり、確率 = FDIST(x,...) であるとき、FINV(確率,...) = x という関係が成り立ちます。
F 確率分布は、2 組のデータのばらつきを比較する F 検定で使用されます。たとえば、合衆国と日本の労働者の年収を比較し、両国で年収の分布に類似性があるかどうかを分析することができます。
確率 F 累積分布に関連する確率を指定します。解説自由度1 自由度の分子を指定します。
自由度2 自由度の分母を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例確率 < 0 または 確率 > 1 である場合、エラー値 #NUM! が返されます。
自由度1、自由度2 に整数以外の値を指定すると、小数点以下が切り捨てられます。
自由度1 < 1 または 自由度1 1010 である場合、エラー値 #NUM! が返されます。
自由度2 < 1 または 自由度2 1010 である場合、エラー値 #NUM! が返されます。
FINV 関数を使用して、F 確率分布の境界値を計算することができます。たとえば、ANOVA 関数の戻り値には、F 統計量、F、有効桁数のレベルが 0.05 である F 境界値に対するデータが含まれることがよくあります。F の境界値を求めるには、FINV 関数の 確率 に有効桁数のレベルを指定するようにします。
FINV 関数の計算には、反復計算の手法が使用されます。確率 の値が指定されると、計算結果の精度が ±3x10-7 以内になるまで反復計算が行われます。反復計算を 100 回行っても結果が収束しない場合は、エラー値 #N/A が返されます。
FINV(0.01,6,4) = 15.20675
(x の値に対するフィッシャー変換を返します)書式 =FISHER(x)この変換の結果、非対称ではなく、ほぼ正規的に分布した関数が生成されます。FISHER 関数は、相関係数に基づく仮説検定を行うときに使用します。
x 関数に代入する値を指定します。解説
x に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例x -1 または x 1 である場合、エラー値 #NUM! が返されます。
フィッシャー変換は、次の数式で表されます。
FISHER(0.75) = 0.972955
(フィッシャー変換の逆関数を返します)書式 =FISHERINV(y)この関数は、データ範囲または配列間の相関を分析する場合に使用します。y = FISHER(x) であるとき、FISHERINV(y) = x という関係が成り立ちます。
y 逆変換の対象となる値を指定します。解説
y に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例
フィッシャー変換の逆関数は、次の数式で表されます。
FISHERINV(0.972955) = 0.75
(既知の値を使用し、将来の値を予測します)書式 =FORECAST(x, 既知のy, 既知のx)予測する値は、x の値に対する y の値です。既知のx と 既知のy から得られる回帰線上で、x の値に対する従属変数 (y) の値を予測します。この関数を使うと、将来の売上高、商品在庫量、消費動向などを予測できます。
x 予測する従属変数の値に対する独立変数の値を、数値で示します。解説既知のy 既知の従属変数の値が入力されているセル範囲または配列を指定します。
既知のx 既知の独立変数の値が入力されているセル範囲または配列を指定します。
x に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例既知のy と 既知のx で指定したセル範囲または配列が空白のとき、または両者のデータ数が異なるときは、エラー値 #N/A が返されます。
既知のx で指定したデータが変動しないとき、エラー値 #DIV/0! が返されます。
FORECAST 関数に対する方程式は a+bx で表されます。このとき
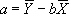
また
FORECAST(30,{6,7,9,15,21},{20,28,31,38,40}) = 10.60725
(範囲内でのデータの頻度分布を、縦方向の数値の配列として返します)書式 =FREQUENCY(データ配列, 区間配列)たとえば、この関数を使うと、試験の成績の範囲内に含まれる成績の頻度分布を計算することができます。この関数では、値は配列として返され、配列数式として入力されます。
データ配列 頻度調査の対象となるデータを含む配列またはセル範囲を指定します。データ配列 に値が含まれていないと、要素としてゼロ (0) を含む配列が返されます。解説区間配列 データ配列 で指定したデータをグループ化するため、値の間隔を配列またはセル範囲として指定します。区間配列 に値が含まれていないと、データ配列 で指定した配列要素の個数が返されます。
FREQUENCY 関数を使うと、隣接するセル範囲が選択された後、そのセル範囲に配列数式として入力されます。このセル範囲にデータの頻度分布が表示されます。使用例返された配列要素の個数は、区間配列 の個数より 1 つだけ多くなっています。この追加された配列要素には、最も高い間隔を超えた値の個数が返されます。たとえば、3 つのセルに入力した 3 つの範囲 (間隔) の値をカウントする場合は、FREQUENCY 関数を 4 つのセルに入力します。余分のセルには、3 つ目の間隔を超えた データ配列 の値の個数が返されます。
引数として指定した配列またはセル範囲に空白セルまたは文字列が含まれている場合、これらは無視されます。
配列を返す数式は、配列数式として入力されている必要があります。配列数式の入力方法の詳細については、ここ をクリックしてください。
テストの成績を入力したワークシートがあります。点数は 79、85、78、85、83、81、95、88、97 で、それぞれセル範囲 A1:A9 に入力されています。データ配列 には、テストの点数を含む列範囲を指定します。区間配列 には、値の間隔を含む列範囲を指定します。この間隔によって、テストの点数がグループ化されます。この使用例では、区間配列 はセル範囲 C4:C6 で、70、79、89 という数値を含みます。次の数式をセル範囲 D4:D7 に配列数式として入力すると、0から70、71から79、80から89、90から100 の各範囲で点数の頻度を計算することができます。ただし、この使用例ではテストの点数が整数であると仮定しています。次の数式は、縦方向に連続する 4 つのセルを選択した後、配列数式として入力します。4 つめの数値 2 は、最も高い間隔 (89) を超えた 2 つの値 (95 と 97) の個数を示します。具体的には
セルD4に=FREQUENCY(A1:A9,C4:C6)を入力し、{Shift}+{Ctrl}+{Enter}で、「配列数式」として確定します。
配列数式とすると数式は、{ }でくくられます。
{=FREQUENCY(A1:A9,C4:C6)}
この式をセルD5からD7まで最終のセル+1行のセルに連続コピーします。
A B C D 戻り値 1 79 2 85 3 78 4 85 70 {=FREQUENCY($A$1:$A$9,C4:C6)} 0 5 83 79 セルD7まで上の式を連続コピー 2 6 81 89 5 7 95 2 8 88 9 97 FREQUENCY(A1:A9,C4:C6) = {0;2;5;2}
配列数式では、複数の計算を行って 1 つまたは複数の結果を返すことができます。
配列数式は、配列引数と呼ばれる複数の値のセットで実行されます。
配列引数には同じ数の行と列を指定する必要があります。
配列数式を作成する方法は、基本的な 1 つの結果を返す数式と同じです。
1 つまたは複数のセルを選択して数式を入力し、Ctrl キーと Shift キーを押しながら Enter キーを押します。1 つの結果を返すために複数の計算が必要な場合があります。
たとえば、次の数式では、セル範囲 A5:A15 の "Blue Sky Airlines" という文字列が入力されているセルと同じ行にある列 D のセルの平均値が計算されます。
IF 関数によって、セル範囲 A5:A15 の "Blue Sky Airlines" と入力されているセルが検索され、セル範囲 D5:D15 にあるセルのうち、検索されたセルと同じ行にあるセルの値が AVERAGE 関数に返されます。{=AVERAGE(IF(A5:A15="Blue Sky Airlines",D5:D15))}
配列数式を使って複数の結果を計算するには、配列引数と同じ行数または列数のセル範囲に配列を入力します。
次の例では、5 つの一連の日付 (列 A) に対し 5 つの一連の売上高 (列 B) を入力すると、TREND 関数によって売上高の直線的な値が返されます。
数式のすべての結果を表示するには、列 C の 5 つのセル (C10:C15) に配列数式を入力します。
{=TREND(B10:B15,A10:A15)}配列数式を使って、ワークシートに入力されていない一連の値を計算し、1 つまたは複数の結果を返すこともできます。
配列数式では、配列以外の数式と同じように定数を使用できますが、配列定数は特定の書式で入力する必要があります。
たとえば、前の例と同じ 5 つの日付と売上高を指定したときに、さらに 2 つの日付を指定して、それらの日付に対応する売上高を予測できます。
数式や関数では配列定数を使用できないため、次の例では、シリアル値を使って TREND 関数の 3 番目の引数に日付を追加します。{=TREND(B10:B15,A10:A15,{35246;35261})}
(F 検定の結果を返します)書式 =FTEST(配列1, 配列2)F 検定により、配列1 と 配列2 とのデータのばらつきに有意な差が認められない片側確率が返されます。FTEST 関数を利用すると、2 つの高等学校で同じテストを実施した場合、両校の生徒の成績に有意な差が認められるかどうかを調べることができます。
配列1 比較対象となる一方のデータを含む配列またはセル範囲を指定します。解説配列2 比較対象となるもう一方のデータを含む配列またはセル範囲を指定します。
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
配列1 または 配列2 のデータ数が 2 未満である場合、または 配列1 と 配列2 のデータがまったく同じである場合、エラー値 #DIV/0! が返されます。
FTEST({6,7,9,15,21},{20,28,31,38,40}) = 0.648318
(ガンマ分布関の値を返します)書式 =GAMMADIST(x, α, β, 関数形式)この関数を使用すると、正規分布に従わないデータの分析を行うことができます。ガンマ分布は、通常、待ち行列分析の中で使われます。
x 関数に代入する値を指定します。解説α 分布に対するパラメータを指定します。
β 分布に対するパラメータを指定します。β = 1 である場合、標準ガンマ分布に従う関数値が返されます。
関数形式 返される関数値の形式を、論理値で指定します。関数形式 に TRUE を指定すると、GAMMADIST 関数の戻り値は累積分布関数の値となり、関数形式 に FALSE を指定すると、GAMMADIST 関数の戻り値は確率量関数の値となります。
x、α、β に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例x < 0 である場合、エラー値 #NUM! が返されます。
α 0 または β 0 である場合、エラー値 #NUM! が返されます。
ガンマ分布は次の式で与えられます。
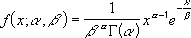
また、標準ガンマ分布は次の式で与えられます。
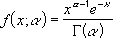
α = 1 である場合、次の式を使って指数分布の値が計算されます。
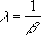
正の整数 n に対して、α = n/2、β = 2、関数形式 = TRUE である場合、自由度 n における (1-CHIDIST(x)) の値が返されます。
α が正の整数である場合、GAMMADIST 関数の戻り値はエルラング分布とも呼ばれます。
GAMMADIST(10,9,2,FALSE) = 0.032639GAMMADIST(10,9,2,TRUE) = 0.068094
(ガンマ累積分布関数の逆関数の値を返します)書式 =GAMMAINV(確率, α, β)つまり、確率 = GAMMADIST(x,...) であるとき、GAMMAINV(確率,...) = x となるような x の値を返します。
この関数は、正規分布に従わないと見られる変数を分析する場合に使います。
解説
確率 ガンマ確率分布における確率を指定します。α 確率分布のパラメータを指定します。
β 確率分布のパラメータを指定します。β = 1 である場合、標準ガンマ分布の値が返されます。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例確率 < 0、または 確率 > 1 である場合、エラー値 #NUM! が返されます。
α 0 または β 0 である場合、エラー値 #NUM! が返されます。
GAMMAINV 関数では、関数値の計算に反復計算の手法が利用されています。確率の値が指定されると、計算結果の精度が ±3x10-7 以内になるまで反復計算が行われます。100 回反復計算を繰り返しても計算結果が収束しない場合、エラー値 #N/A が返されます。
GAMMAINV(0.068094,9,2) = 10
(ガンマ関数 G(x) の値の自然対数を返します)書式 =GAMMALN(x)
x GAMMALN 関数に代入する数値を指定します。解説
x に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例x 0 である場合、エラー値 #NUM! が返されます。
i を整数とするとき、自然対数の底 e の GAMMALN(i) 乗は (i-1)! と等しくなります。
GAMMALN 関数の値は、次の数式で計算されます。
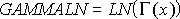
ここで
GAMMALN(4) = 1.791759EXP(GAMMALN(4)) = 6 = (4-1)!
(正の数からなる配列またはセル範囲のデータの相乗平均を返します)GEOMEAN 関数を利用すると、利率が変動する場合の複利計算で、平均成長率を計算することができます。
書式 =GEOMEAN(数値1, 数値2, ...)
数値1,数値2,... 相乗平均を計算するため、最大 30 個までの数値を指定できます。半角のカンマ (,) で区切られた引数の代わりに、数値配列または配列に対するセル参照を指定することもできます。解説
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
引数に 0 以下の数値が含まれていると、エラー値 #NUM! が返されます。
相乗平均は次の式で与えられます。
GEOMEAN(4,5,8,7,11,4,3) = 5.476987
既にわかっているデータを使用して指数曲線を予測し、指定された 既知のy と 既知のx のデータを使用して 新しいx の配列に対する y の値を計算します。GROWTH ワークシート関数を使うと、既知のy と 既知のx のデータを指数曲線に当てはめることもできます。書式 =GROWTH(既知のy, 既知のx, 新しいx, 定数)
既知のy 既にわかっている y の値の系列で、y = b*m^x という関係になります。解説既知のy の配列が 1 つの列に入力されている場合、既知のx の各列はそれぞれ異なる変数であると見なされます。
既知のy の配列が 1 つの行に入力されている場合、既知のx の各行はそれぞれ異なる変数であると見なされます。
既知のy のいずれかの値が 0 または負の数であると、GROWTH 関数の計算はエラー値 #NUM! となります。
既知のx 既にわかっている x の値の系列で、y = b*m^x という関係になります。この引数は省略してもかまいません。既知のx の配列には、1 つまたは複数の変数の系列を指定することができます。変数の系列が 1 つである場合、既知のy と 既知のx は、両者の次元が同じであれば、どのような形の範囲であってもかまいません。変数の系列が複数である場合、既知のy は 1 行または 1 列のセル範囲でなければなりません。
既知のx を省略すると、既知のy と同じサイズの {1,2,3...} という配列を指定したと見なされます。
新しいx GROWTH 関数を利用して、対応する y の値を計算する新しい x の値を指定します。新しいx には、既知のx と同様にそれぞれ独立した変数が入力されている 1 つの列 (または 1 つの行) を指定する必要があります。既知のy が 1 つの列に入力されている場合、既知のx と 新しいx は同じ列数でなければなりません。また、既知のy が 1 つの行に入力されている場合、既知のx と 新しいx は同じ行数でなければなりません。
新しいx を省略すると、既知のx と同じ値であると見なされます。
既知のx と 新しいx の両方を省略すると、既知のy と同じサイズの {1,2,3,...} という配列を指定したと見なされます。
定数 定数 b を 1 にするかどうかを、論理値で指定します。定数 にTRUE を指定するか省略すると、bの値も計算されます。
定数 に FALSE を指定すると、b の値が 1 に設定され、y = m^x となるように m の値が調整されます。
計算結果が配列となる数式は、適切なセル範囲を選択した後、その中に配列数式として入力する必要があります。配列数式の入力方法の詳細については、 をクリックしてください。使用例既知のx のような引数に配列定数を指定するとき、同じ行の値を区切るには半角のカンマ (,) を使い、各行を区切るには半角のセミコロン (;) を使います。
次の例では、LOGEST 関数の使用例と同じデータを使っています。第 11 期から第 16 期までの売上がそれぞれ 33,100、47,300、69,000、102,000、150,000、220,000 ユニットであったとします。これらの値を 1 つの列に入力し、このセル範囲に "ユニット売上" という名前を定義したとします。セル範囲 B8:B9 を選択し、次の数式を配列数式として入力すると、前の 6 期の売上から次の 2 期の売上を予測することができます。
GROWTH(ユニット売上,{11;12;13;14;15;16},{17;18}) = {320197;468536}
売上の傾向が今後も指数曲線で近似できるとすれば、第17期、第18期には、それぞれ 320197、468536 ユニットの売上が見込めます。
連続する数値であれば、既知のx の値として何を指定してもかまいません。たとえば、既知のx として {1;2;3;4;5;6} を使うときは、次のような配列数式を入力します。
GROWTH(ユニット売上,,{7;8},) = {320197;468536}
1 組の数値の調和平均を返します。調和平均は、逆数の算術平均 (相加平均) に対する逆数として定義されます。書式 =HARMEAN(数値1, 数値2, ...)
数値1,数値2,... 計算の対象となる最大 30 個までの数値を指定します。半角のカンマ (,) で区切った数値の代わりに、配列または配列に対するセル参照を指定することもできます。解説
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセルを指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
引数に 0 以下の数値が含まれていると、エラー値 #NUM! が返されます。
相加平均、相乗平均、調和平均の間には次のような関係が成立します。
調和平均 相乗平均 相加平均
調和平均は次の式で計算されます。
HARMEAN(4,5,8,7,11,4,3) = 5.028376
(超幾何分布関数の値を返します)書式 =HYPGEOMDIST(標本の成功数, 標本数, 母集団の成功数, 母集団の大きさ)HYPGEOMDIST 関数では、指定された標本数、母集団の成功数、母集団の大きさから、一定数の標本が成功する確率を計算します。HYPGEOMDIST 関数は、一定の母集団を対象とした分析に使います。
ただし、それぞれの事象は成功または失敗の 2 つの状態だけで、分析の対象となる標本は母集団から無作為に抽出されるとします。
標本の成功数 標本内で成功する数を指定します。解説標本数 標本数を指定します。
母集団の成功数 母集団内で成功する数を指定します。
母集団の大きさ 母集団全体の数を指定します。
引数に小数点以下の値を指定しても切り捨てられます。使用例引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。
標本の成功数 に負の数を指定した場合、または 標本の成功数 が 標本数 または 母集団の成功数 よりも大きい場合、エラー値 #NUM! が返されます。
標本の成功数 に負の数を指定した場合、または 標本の成功数 が (標本数-母集団の大きさ+母集団の成功数) よりも小さい場合、エラー値 #NUM! が返されます。
標本数 に負の数を指定した場合、または 標本数 が 母集団の大きさ よりも大きい場合、エラー値 #NUM! が返されます。
母集団の成功数 に負の数を指定した場合、または 母集団の成功数 が 母集団の大きさ よりも大きい場合、エラー値 #NUM! が返されます。
母集団の大きさ に負の数を指定した場合、エラー値 #NUM! が返されます。
超幾何分布は次の式で与えられます。
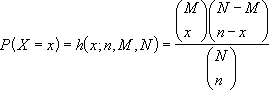
ここで
x = 標本の成功数
n = 標本数
M = 母集団の成功数
N = 母集団の大きさ
HYPGEOMDIST 関数では、置き換えなしに一定の母集団から標本が抽出されます。
20 個のチョコレートが入ったパッケージがあるとします。20 個のうち 8 個はムース入りで、12 個はナッツ入りです。このパッケージから 4 個のチョコレートを無作為に抽出するとき、その中の 1 個がムース入りである確率は、次の数式で計算することができます。
HYPGEOMDIST(1,4,8,20) = 0.363261
(既知のx と 既知のy を通過する線形回帰直線の切片を計算します)切片とは 既知のx と 既知のy の値を通過する回帰直線が y 軸と交わる座標のことです。この切片は、独立変数が 0(ゼロ) である場合の従属変数の値を求めるときに使用します。たとえば、室温またはそれ以上の環境で、ある金属の電気抵抗値が実験的にわかっている場合、INTERCEPT 関数を利用することにより、気温 0゚C での電気抵抗値を予測することができます。
書式 =INTERCEPT(既知のy, 既知のx)
既知のy 観測またはデータの従属範囲を指定します。解説既知のx 観測またはデータの独立範囲を指定します。
引数には、数値、あるいは数値を含む名前、配列、またはセル参照を指定します。使用例引数として指定した配列やセル参照に、文字列、論理値、または空白セルが含まれる場合、これらの値は無視されます。ただし、値が 0 であるセルは、計算の対象となります。
既知のy と 既知のx に含まれる値の個数が異なる場合や、これらの引数に値がまったく含まれない場合は、エラー値 #N/A が返されます。
回帰直線の切片は、次の数式で表されます。
また、回帰直線の傾きは、次の数式で表されます。
INTERCEPT({2,3,9,1,8},{6,5,11,7,5}) = 0.048387
(引数として指定したデータの尖度を返します)書式 =KURT(数値1, 数値2, ...)尖度とは、対象となるデータの分布を標準分布と比較して、度数分布曲線の相対的な鋭角度または平たん度を表した数値です。尖度が正の数になる場合、度数分布曲線が相対的に鋭角になっていることを表し、負の数になる場合は、相対的に平たんになっていることを表します。
数値11,数値2,... 尖度を計算するため、最大 30 個までの数値を指定します。半角のカンマ (,) で区切った数値の代わりに、配列または配列に対するセル参照を指定することもできます。解説
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
4 つ以上のデータがそろっていない場合、または標本の標準偏差が 0 (ゼロ) に等しい場合、エラー値 #DIV/! が返されます。
尖度は次のように定義されます。
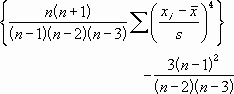
ここでs は標本に基づいた標準偏差を表します。
KURT(3,4,5,2,3,4,5,6,4,7) = -0.1518
(1 組のデータの中で 順位 番目に大きなデータを返します)書式LARGE 関数を利用すると、相対的な順位に基づいて、データの中から特定の値を選択することができます。たとえば、LARGE 関数を使って、テストの最高点、第 2 位または第 3 位の得点などを調べることができます。
LARGE(範囲, 順位)解説範囲 抽出の対象となるデータが入力されているセル範囲または配列を指定します。
順位 抽出する値の順位 (大きい方から数えた) を数値で指定します。
範囲 にデータが含まれていないと、エラー値 #NUM! が返されます。使用例順位 0 である場合、または 順位 が対象となるデータの個数よりも大きい場合、エラー値 #NUM! が返されます。
n を 範囲 に含まれているデータの個数とするとき、LARGE(範囲,1) は対象となるデータの最大値を返します。また、LARGE(範囲,n) は対象となるデータの最小値を返します。
LARGE({3,4,5,2,3,4,5,6,4,7},3) = 5LARGE({3,4,5,2,3,4,5,6,4,7},7) = 4
最小二乗法を使って、指定したデータに最もよく当てはまる直線を算出し、この直線を記述する係数と y 切片との配列を返します。LINEST 関数では、値は配列として返され、配列数式として入力されます。配列数式の入力方法の詳細については、ここをクリックしてください。書式 =LINEST(既知のy, 既知のx, 定数, 補正)直線の方程式は次のように書くことができます。
y = mx + b または y = m1x1 + m2x2 + ... + b (独立変数 x の範囲が複数の場合)
ここで、従属変数の y は独立変数 x の関数です。また、m はそれぞれの x に対応する係数で、b は y 切片と呼ばれる定数です。y、x、m はベクトル (1次元の配列) であることに注意してください。LINEST 関数によって返される配列は、{mn,mn-1,...,m1,b} となります。また、同時に、回帰直線に関する補正項の配列も返されます。
既知のy 既にわかっている y の値の系列で、y = mx + b という関係になります。解説既知のy の配列が 1 つの列に入力されている場合、既知のx の各列はそれぞれ異なる変数であると見なされます。
既知のy の配列が 1 つの行に入力されている場合、既知のx の各行はそれぞれ異なる変数であると見なされます。
既知のx 既にわかっている x の値の系列で、y = mx + b という関係になります。この引数は省略してもかまいません。既知のx の配列には、1 つまたは複数の変数の系列を指定することができます。変数の系列が 1 つである場合、既知のy と 既知のx は、両者の次元が同じであれば、どのような形の範囲であってもかまいません。変数の系列が複数である場合、既知のy は 1 行または 1 列のセル範囲でなければなりません。
既知のx を省略すると、既知のy と同じサイズの {1,2,3,...} という配列であると見なされます。
定数 定数 b を 0 にするかどうかを、論理値で指定します。定数 に TRUE を指定するか省略すると、b の値も計算されます。
定数 に FALSE を指定すると、b の値が 0 に設定され、y = mx となるように m の値が調整されます。
補正 回帰直線の補正項を追加情報として返すかどうかを論理値で指定します。補正 に TRUE を指定すると、回帰直線の補正項が返され、計算結果の配列は {mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r2,sey;F,df;ssreg,ssresid} となります。
補正 に FALSE を指定するか省略すると、係数 m と定数 b のみの配列が返されます。
次のような回帰直線の補正項が返されます。
補正項 説明 se1,se2,...,sen 係数 m1,m2,...,mn に対する標準誤差の値です。 Seb 定数 b に対する標準誤差の値です (定数 が FALSE の場合、seb = #N/A となります)。 r2 確実度の係数。予測される y の値と実際の y の値を比較して、0 から 1 の範囲の数値を計算します。この数値が 1 である場合、標本に完全な相関関係が存在することになります (予測される y の値と実際の y の値の間に差異はありません)。逆にこの係数の値が 0 である場合、回帰直線の方程式は y の値を予測するためにほとんど役立ちません。r2 がどのように計算されるかは、後述の注意を参照してください。 sey 予測される y の値に対する標準誤差です。 F F 検定、または F 検定と認められる値です。F 検定を利用すると、独立変数と従属変数の間で観察された関係が偶然によるものかどうかを決定することができます。 df 自由度です。自由度を利用すると、統計表の中で F の臨界値を見つけるために役立ちます。統計表の中で見つけた値と、LINEST 関数が返す F 検定を比較することにより、モデルの信頼性の度合いを決めることができます。 ssreg 回帰の平方和です。 ssresid 残余の平方和です。 次の図は、追加の補正項が配列として返される順序を示します。
任意の直線は、傾きと y 切片を使って記述することができます。使用例 1 傾きと y 切片
傾き (m):
直線の傾き (m) を求めるには、直線上の 2 点の座標が (x1,y1)、(x2,y2) で表されるとき、(y2 - y1)/(x2 - x1) で計算できます。y 切片 (b):
直線の y 切片 (b) とは、直線が y 軸と交わるときの y の値です。直線の方程式は y = mx + b で表されます。m と b の値がわかれば、y または x の値をこの方程式に代入することにより、直線上の任意の点の座標を計算することができます。このような計算を行うために TREND 関数を利用できます。
独立変数 x が 1 つしかわからないときは、次の数式を使って、傾き (m) と y 切片 (b) を計算することができます。
傾き (m):
INDEX(LINEST(既知のy,既知のx),1)y 切片 (b):
INDEX(LINEST(既知のy,既知のx),2)LINEST 関数で計算した直線の精度は、指定したデータのばらつきによって決まります。データの分布がより直線に近ければ、それだけ LINEST 関数のモデルの精度は向上します。LINEST 関数では、データに最もよく合う直線を見つけるために最小二乗法を使用しています。独立変数 x の値が 1 つでもわかれば、次の数式を使って m と b の値が計算されます。
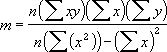
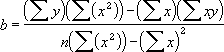
直線/指数曲線回帰関数である LINEST 関数と LOGEST 関数は、データにより適合する直線または指数曲線を近似計算します。データを直線で近似するか、指数曲線で近似するかは、データに合わせて選択する必要があります。計算によって取得した直線または指数曲線がデータに適合しているかどうかは、次の方法で調べます。
直線の場合は、TREND(既知のy,既知のx)、指数曲線の場合は GROWTH(既知のy, 既知のx) を使って計算を行います。これらの関数は、引数として 新しいx を指定しなくても、直線または指数曲線上で、実際のデータに対応する y の値を予測計算し、y の予測値の配列を返します。両者の値を一目で比較できるようにグラフを作成する方法もあります。
回帰分析を行う際、直線上の各点で、その点における予測される y の値と実際の y の値の差の平方が計算されます。このようにして計算した差の平方の和を "残余の平方和" と呼びます。次に、実際の y の値と y の平均値の差の平方和が計算されます。これらの和を "総平方和" と呼びます (回帰の平方和+残余の平方和)。総平方和と比較し、残余の平方和が小さければ小さいほど、確実度の係数である r2 の値が大きくなり、回帰分析で得られた方程式が変数間の関係をより正確に表していることになります。
計算結果が配列となる数式は、配列数式として入力する必要があります。配列数式を入力する方法については、ここをクリックしてください。
既知のx のような引数に配列定数を指定するとき、同じ行の値を区切るには半角のカンマ (,) を使い、各行を区切るには半角のセミコロン (;) を使います。
回帰方程式によって予測計算された y の値は、方程式を決定するときに使用した y の値の範囲外では、適切な値にならない場合があります。
LINEST({1,9,5,7},{0,4,2,3}) = {2,1} となり、傾きが 2 で y 切片が 1 の直線となります。使用例 2 1 変数の線形回帰
ある年度の最初の 6 か月間に、3,100 万円、4,500 万円、4,400 万円、5,400 万円、7,500 万円、8,100 万円の売上があったとします。これらの値がセル範囲 B2:B7 に入力されているとすると、次のような 1 変数の線形回帰モデルを使って、9 番目の月の売上を予測計算することができます。使用例 3 多変数の線形回帰SUM(LINEST(B2:B7)*{9,1}) = SUM({1000,2000}*{9,1}) = 11,000 万円
一般に、SUM({m,b}*{x,1}) = mx + b となり、指定した x の値に対する y の値を予測計算できます。同じ計算を行うために TREND 関数を利用してもかまいません。
ある不動産会社がビジネス街にある中古オフィスの買収に乗り出そうと考えています。この不動産会社は、多数の線形回帰分析を使い、次の変数に基づいて、オフィス ビルの価格を評価しようとしました。使用例 4 F 検定と R-2 乗検定の使い方
変数 内容 y オフィス ビルの評価額 (単位 : 万円) x1 床面積 (単位 : ?) x2 オフィスの数 x3 入口の数 x4 建築後の年数 (単位 : 年) この使用例では、それぞれの独立変数 (x1, x2, x3, x4) と従属変数 (y) との間に線形の関係が成立することが前提になっています。
この不動産会社では、1,500 にのぼる物件の中から 11 のオフィス ビルを選択し、次のようなデータを得ることができました。
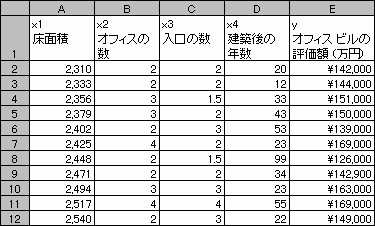
"半分の入口" とは通用口を意味します。配列として入力するとき、次の数式の計算結果は次の表のようになります。
LINEST(E2:E12,A2:D12,TRUE,TRUE)
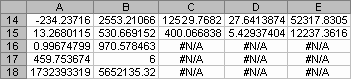
多変数の回帰方程式 y = m1*x1 + m2*x2 + m3*x3 + m4*x4 + b は、14 行目に表示されている値を使って次のように決定されます。y = 27.64*x1 + 12,530*x2 + 2,553*x3 - 234.24*x4 + 52,318
床面積が 2,500 ?で 3 つのオフィスがあり、出口が 2 つで築 25 年のオフィス ビルがあるとすると、その評価額は次の数式で計算できます。
y = 27.64*2500 + 12530*3 + 2553*2 - 234.24*25 + 52318 = 158,258 (万円)
評価額は、TREND 関数を使って計算することもできます。
使用例 3 では、確実度係数 r2, が 0.99675 という値になっており (計算結果のセル A16 の値)、複数の独立変数と従属変数 (評価額) との間に強い相関があることが示されています。さらに F 検定を利用すると、このように高い r2 の値が偶然の結果であるかどうかを調べることができます。使用例 5 t 検定の計算実際には変数間に相関関係など存在せず、偶然、特異な 11 例を選択した結果、統計的に強い相関関係が観測されたと仮定します。このように、相関関係が存在すると誤って結論づけを行うがい然性を "アルファ" と呼びます。
F の観測値が、F の臨界値よりも大きい場合、変数間に相関関係が存在すると見なされます。F の臨界値は、統計学の教科書などに掲載されている一覧表を参考にして調べることができます。一覧表を読むときは、アルファの値を 0.05 とし、自由度 (ほとんどの場合、v1、v2 と省略されます) を v1 = k = 4、v2 = n - (k + 1) = 11 - (4 + 1) = 6 とします。ここで、k は回帰分析を行う変数の個数で、n はデータの個数とします。この結果、F の臨界値は 4.53 と計算されます。
一方、F の観測値は 459.753674 (セル A17 の値) となり、4.53 というF の臨界値と比較するとはるかに大きな値になります。このようにして F 検定を行った結果、回帰分析によって得た方程式は、オフィス ビルの評価額を決める上で役に立つことが明らかになります。
もう 1 つの仮説検定を使うと、直線の傾きを表すそれぞれの係数が使用例 3 でオフィス ビルの評価額を予測するために有効であるかを調べることができます。たとえば、築後年数の係数が統計的に有意であるかどうか調べるには、-234.24 (築後年数の係数) を 13.268 (セル A15 に表示されている築後年数の係数についての標準誤差の予測値) で除算します。次の数式により、t の観測値が計算できます。t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
統計学の教科書を参考にすると、自由度 6 、アルファ 0.05 として、t の臨界値は 1.94 であることがわかります。t の観測値の絶対値は 17.7 で、臨界値の 1.94 よりもはるかに大きいため、築後年数は、オフィス ビルの評価額を予測するため、重要な変数であることがわかります。その他の独立変数についても同じ方法で統計的有意性を調べることができます。次に、それぞれの独立変数に対する t の観測値の一覧を示します。
変数 t の観測値 床面積 5.1 オフィスの数 31.3 入口の数 4.8 建築後の年数 17.7 これらの値の絶対値はすべて 1.94 よりも大きくなるため、回帰方程式のすべての変数が、オフィス ビルの評価額を予測する上で有効であることを確認できます。
回帰分析において、指定されたデータに最もよく当てはまる指数曲線を算出し、この曲線を表す係数の配列の値を返します。LOGEST 関数は、配列の値を数式として返します。配列数式の詳細については、 ここをクリックしてください。書式 =LOGEST(既知のy, 既知のx, 定数, 補正)指数曲線は、次の数式で表されます。
y = b*m^x
また、独立変数が複数ある場合は
y = (b*(m1^x1)*(m2^x2)*_)
従属変数の y は独立変数 x の関数です。また、m はそれぞれの x のべき乗に対応する底で、b は定数です。y、x、m がベクトル (1 次元配列) であることに注意してください。LOGEST 関数が返す配列は、{mn,mn-1,...,m1,b} となります。
既知のy 既にわかっている y の値の系列で、y = b*m^x という関係になります。解説既知のy の配列が 1 つの列に入力されている場合、既知のx の各列はそれぞれ別個の変数であると見なされます。
既知のy の配列が 1 つの行に入力されている場合、既知のx の各行はそれぞれ別個の変数であると見なされます。
既知のx 既にわかっている x の値の系列で、y = b*m^x という関係になります。この引数は省略することができます。既知のx の配列には、変数の系列を指定することができます。変数を 1 つしか使用しない場合、既知のy と 既知のx には、双方の次元が同じである限り、どのような形の範囲でも指定できます。複数の変数を使用する場合、既知のy はセル範囲 (1 行または 1 列の範囲で、ベクトル範囲とも呼ばれます) である必要があります。
既知のx を省略すると、既知のy と同じサイズの配列 {1,2,3,...} が使用されます。
定数 定数 b を 1 にするかどうかを論理値で指定します。定数 に TRUE を指定するかまたは省略すると、b の値も計算されます。
定数 に FALSE を指定すると、b の値が 1 に設定され、y = m^x となるように m の値が調整されます。
補正 回帰指数曲線の補正項を追加情報として返すかどうかを、論理値で指定します。補正 に TRUE を指定すると、回帰指数曲線の補正項が返され、計算結果の配列は {mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r 2,sey;F,df;ssreg,ssresid} となります。
補正 に FALSE を指定するか省略すると、底 m と定数 b のみの配列が返されます。
追加情報である補正項の詳細については LINEST 関数を参照してください。
データをプロットした結果が指数曲線に近づけば近づくほど、計算によって求められた指数曲線はより正確にデータに適合します。LINEST 関数と同様に、LOGEST 関数は変数間の相関関係を記述する数値の配列を返しますが、LINEST 関数は直線にデータを適合させるのに対して、LOGEST 関数は指数曲線にデータを適合させます。詳細については LINEST 関数を参照してください。
独立変数 x が 1 つしかわからないときは、次の数式を使って、底 (m) と y 切片 (b) を計算することができます。使用例
底 (m):
INDEX(LOGEST(既知のy,既知のx),1)y 切片 (b):
INDEX(LOGEST(既知のy,既知のx),2)方程式 y = b*m^x を使って、計算によって y の値を予測することができますが、このような計算を行うため、Excel には GROWTH 関数が用意されています。詳細については GROWTH 関数を参照してください。
計算結果が配列となる数式は、配列数式として入力する必要があります。配列数式の入力方法の詳細については、 ここをクリックしてください。
既知のx のような引数に対し、配列定数を入力するときは、半角のカンマ (,) を使って同じ行の値を区切り、半角のセミコロン (;) を使って異なる行を区切ります。
回帰方程式によって予測計算された y の値は、方程式を決定するときに使用した y の値の範囲外では、適切な値にならない場合があります。
新製品を市場に出荷すると、ある時点まではネズミ算式に売上が伸びることが経験的にわかっています。連続する 6 か月間にある製品の売上が 33100、47300、69000、102000、150000、220000 ユニットという伸びを示しました。これらの値を 1 つの列に入力し、このセル範囲に "ユニット売上" という名前を定義したとしましょう。セル範囲 D1:E5 を選択し、次の数式を配列数式として入力します。重要LOGEST(ユニット売上,{11;12;13;14;15;16},TRUE,TRUE)
セル範囲 D1:E5 の計算結果は次のようになります。{1.46327563,495.30477;0.0026334,0.03583428;0.99980862,0.01101631;20896.8011,4;2.53601883,0.00048544}
この結果から、データに適合する指数曲線方程式は
y = 495.3 * 1.4633x
となります。
この方程式を使って計算をすると、7 か月目以降の売上を予測することができますが、通常は GROWTH 関数を使ってこの計算を行います。詳細については GROWTH 関数を参照してください。
追加の補正項に関する情報 (上記の配列 D2:E5) を利用すると、y の値を予測計算する場合に、前述の方程式が有効であるかどうかを調べることができます。
LOGEST 関数を使って方程式の妥当性を調べる方法は、基本的に LINEST 関数で使った方法と同じです。ただし、LOGEST 関数が計算する補正項は、次のような線形モデルに基づいています。ln y = x1 ln m1 + ... + xn ln mn + ln b
補正項、特に sei と seb を評価するときには、このことに注意してください。つまり、mi と b を直接比較するのではなく、ln mi と ln b を比較するようにします。詳細については統計学の専門書を参照してください。
配列数式では、複数の計算を行って 1 つまたは複数の結果を返すことができます。配列数式は、配列引数と呼ばれる複数の値のセットで実行されます。配列引数には同じ数の行と列を指定する必要があります。配列数式の作成方法は他の数式とほぼ同じですが、数式の入力時に Ctrl キーと Shift キーを押しながら Enter キーを押します。1 つの結果を返す配列数式
1 つの結果を返すために複数の計算が必要な場合があります。たとえば、次のワークシートでは、3 つの製品部門を持つヨーロッパ支社と北米支社で、1992 年のヨーロッパ支社の製品部門別の平均収益を計算します。複数の結果を返す配列数式
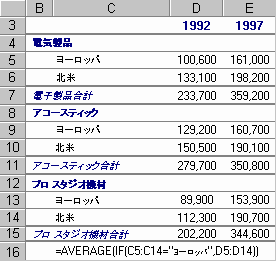
セル C16 に配列数式 =AVERAGE(IF(C5:C14="Europe",D5:D14)) が入力されています。この数式により、セル範囲 C5:C14 で "Europe" という文字列が入力されているセルが検索され、検索されたセルと同じ行にある列 D のセルの平均値が計算されます。
配列数式を使って複数の結果を計算するには、配列引数と同じ行数または列数のセル範囲に配列を入力します。次の例では、3 か月 (列 3) に 3 つの一連の売上高 (列 5) を入力すると、TREND 関数によって売上高の直線的な値が返されます。数式のすべての結果を表示するには、列 6 の 3 つのセル (C6:E6) に配列数式を入力します。定数を使用した配列数式
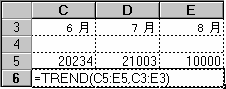
配列数式として =TREND(C5:E5,C3:E3) を入力すると、3 つの売上高と月から 3 つの結果が返されます。
配列数式を使って、ワークシートに入力されていない一連の値を計算し、1 つまたは複数の結果を返すこともできます。配列数式では、配列以外の数式と同じように定数を使用できますが、配列定数は特定の書式で入力する必要があります。たとえば、前の例と同じ 3 つの売上高を指定したときに、次の 2 か月の売上高を予測できます。追加情報
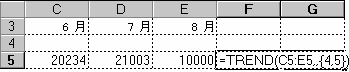
最初の 3 か月の結果から 4、5 か月目の売上高を予測するには、数式 =TREND(C5:E5,,{4,5}) を入力します。
配列数式で変化しない値の詳細については、ここをクリックしてください。配列数式の入力方法については、ここをクリックしてください。
基本的な、1 つの結果を返す数式では、1 つまたは複数の引数または値から 1 つの結果が返されます。1 つの結果を返す数式には、値を含むセルの参照、または値自体を入力できます。通常はセル範囲の参照が使用される配列数式に、セル範囲に入力されている値の配列を入力することもできます。入力する値の配列は配列定数と呼ばれ、一般的には、各セルに値を個別に入力しない場合に使います。配列定数を作成するには、次の操作を行います。中かっこ ({ }) で囲んだ値を数式に直接入力します。
異なる列の値をカンマ (,) で区切ります。
異なる行の値をセミコロン (;) で区切ります。
たとえば、ある行の 4 つのセルにそれぞれ「10」、「20」、「30」、「40」と入力する代わりに、配列数式に {10,20,30,40} と入力できます。この配列定数は、1 × 4 配列と呼ばれ、1 行× 4 列のセル範囲の参照と同じです。ある行の各セルに「10」、「20」、「30」、「40」と入力し、すぐ下の行の各セルに「50」、「60」、「70」、「80」と入力する場合は、2 × 4 配列の配列定数 {10,20,30,40;50,60,70,80} を入力します。配列定数で使用できる値の詳細については、ここをクリックしてください。
配列定数には、数値、文字列、TRUE や FALSE などの論理値、および #N/A などのエラー値を使用できます。配列定数の数値には、整数、小数、および科学技術計算の書式を使用できます。
文字列は、"Tuesday" のようにダブル クォーテーション (") で囲む必要があります。
{1,3,4;TRUE,FALSE,TRUE} のように、同じ配列定数内で異なるデータ型の値を使用できます。
配列定数の値は、数式ではなく定数である必要があります。
配列定数に使用できない文字列などドル記号 ($)、かっこ(( ))、またはパーセント記号 (%) は使用できません。
セル参照は使用できません。
長さが異なる列または行は使用できません
配列数式を入力すると、中かっこ ({ }) の間に数式が自動的に挿入されます。配列数式が 1 つの結果を返す場合は、配列数式を入力するセルをクリックします。
配列数式が複数の結果を返す場合は、配列数式を入力するセル範囲を選択します。配列数式を入力します。
Ctrl キーと Shift キーを押しながら Enter キーを押します。
(x の対数正規型の累積分布関数の逆関数を返します)書式 =LOGINV(確率, 平均, 標準偏差)ln(x) は、引数 平均 と 標準偏差 による正規型分布で、p = LOGNORMDIST(x,...) であるとき、LOGINV(p,...) = x となります。
対数正規型分布は、対数的に変換されたデータを分析する場合に使用します。
確率 対数正規型分布に伴う確率を指定します。解説平均 ln(x) の平均値を指定します。
標準偏差 ln(x) の標準偏差を指定します。
対数正規型分布関数の逆関数は、次の数式で表されます。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例
確率 <= 0 または 確率 >= 1 である場合、エラー値 #NUM! が返されます。
標準偏差 <= 0 である場合、エラー値 #NUM! が返されます。
LOGINV(0.039084,3.5,1.2) = 4.000014
(対数正規累積分布関数の値を返します)書式 =LOGNORMDIST(x, 平均, 標準偏差)対数正規分布は、対数化されたデータの分析によって利用できます。
x 関数に代入する値を指定します。解説平均 In (x) (x の自然対数) の平均値を指定します。
標準偏差 ln (x) (x の自然対数) の標準偏差を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例x 0 または 標準偏差 0 である場合、エラー値#NUM! が返されます。
対数正規分布関数は次のように定義されています。
LOGNORMDIST(4,3.5,1.2) = 0.039084
(引数リストに含まれる最大の数値を返します)書式 =MAX(数値1, 数値2, ...)
数値1, 数値2, ... 最大の数値を見つけるため、1 ? 30 個までの数値を指定することができます。使用例引数には、数値、空白セル、論理値、または数値を表す文字列を指定することができます。エラー値または数値に変換できない文字列を指定すると、エラーになります。
引数に配列またはセル範囲の参照を指定した場合、その中に含まれる数値だけが計算の対象となります。配列やセル範囲に含まれる空白セル、論理値、または文字列はすべて無視されます。論理値、および文字列を処理する場合は、MAXA 関数を使用してください。
引数の中に数値が含まれていない場合、MAX 関数の計算結果は 0(ゼロ) となります。
次の例は、セル範囲 A1:A5 に 10、7、9、27、2 という数値が入力されている場合です。MAX(A1:A5) = 27
MAX(A1:A5,30) = 30
(引数リストに含まれる最大の数値を返します)書式 =MAXA(数値1, 数値2,...)文字列や、TRUE、FALSE などの論理値も数値と同じように比較の対象になります。
MAXA 関数は MINA 関数とよく似た関数です。詳細については、MINA 関数の使用例を参照してください。
解説
数値1, 数値2,... 最大の値を見つけるため、1 ? 30 個までの数値を指定します。
引数には、数値、空白セル、論理値、または数値を表す文字列を指定することができます。エラー値を指定すると、エラーになります。計算の対象に文字列または論理値を含めない場合は、MAX ワークシート関数を使用してください。使用例引数に配列またはセル範囲の参照を指定した場合、そこに含まれる数値だけが計算の対象となります。配列またはセル範囲の参照に含まれる空白セルと文字列は無視されます。
引数に TRUE が含まれている場合は 1 と見なされ、文字列または FALSE が含まれている場合は 0 (ゼロ) と見なされます。
引数の中に数値が含まれていない場合、MAXA 関数の計算結果は 0 (ゼロ) となります。
次の例は、セル範囲 A1:A5 に 10、7、9、27、2 という数値が入力されている場合です。MAXA(A1:A5) = 27
MAXA(A1:A5,30) = 30
次の例は、セル範囲 A1:A5 に 0、0.2、0.5、0.4、TRUE という値が入力されている場合です。
MAXA(A1:A5) = 1
(引数リストに含まれる数値のメジアン (中央値) を返します)書式 =MEDIAN(数値1, 数値2, ...)メジアンとは、引数リストの数値を小さいものから大きなものに順に並べたとき、その中央にくる数値のことです。つまり、メジアンより小さな数値と、メジアンより大きな数値の個数が等しくなります。
解説
数値1,数値2,... メジアンを計算するため、1 個から 30 個までの数値を指定することができます。引数には、数値、あるいは数値を含む名前、配列、またはセル範囲を指定できます。
引数として指定した配列やセル範囲に、文字列、論理値、または空白セルが含まれる場合、これらの値は無視されます。ただし、値が 0 であるセルは、計算の対象になります。
引数として指定した数値の個数が偶数である場合、中央に位置する 2 つの数値の平均が計算されます。この場合の例は、2 番目の使用例を参照してください。使用例
MEDIAN(1,2,3,4,5) = 3MEDIAN(1,2,3,4,5,6) = 3.5 (3 と 4 の平均値)
(引数リストに含まれる最小の数値を返します)書式 =MIN(数値1, 数値2, ...)
数値1,数値2,... 最小の数値を見つけるため、1 ? 30 個までの数値を指定することができます。使用例引数には、数値、空白セル、論理値、または数値を表す文字列を指定することができます。エラー値または数値に変換できない文字を指定するとエラーになります。
引数として、配列やセル範囲の参照を指定した場合、その中に含まれる数値だけが計算の対象になります。配列やセル範囲に含まれる空白セル、論理値、または文字列はすべて無視されます。論理値や文字列を処理する場合は、MINA 関数を使用してください。
引数の中に数値が含まれていない場合、MIN 関数の計算結果は 0 となります。
次の例は、セル範囲 A1:A5 に 10、7、9、27、2 という数値が含まれている場合です。MIN(A1:A5) = 2
MIN(A1:A5,0) = 0
MAX 関数は MIN 関数とよく似た関数です。MAX 関数の使用例も参照してください。
(引数リストに含まれる最小の数値を返します)書式 =MINA(数値1, 数値2,...)文字列や、TRUE、FALSE などの論理値も数値と同じように比較の対象になります。
使用例
数値1, 数値2,... 最小値を見つけるため、1 ? 30 個までの数値を指定します。引数には、数値、空白セル、論理値、または数値を表す文字列を指定することができます。エラー値を指定すると、エラーになります。計算の対象に文字列または論理値を含めない場合は、MIN ワークシート関数を使用してください。
数に配列またはセル範囲の参照を指定した場合、そこに含まれる数値だけが計算の対象となります。配列またはセル範囲の参照に含まれる空白セルと文字列は無視されます。
引数に TRUE が含まれている場合は 1 と見なされ、文字列または FALSE が含まれている場合は 0 (ゼロ) と見なされます。
引数の中に数値が含まれていない場合、MINA 関数の計算結果は 0 (ゼロ) となります。
セル範囲 A1:A5 に 10、7、9、27、2 という数値が入力されている場合の計算結果は、次のとおりです。MINA(A1:A5) = 2
MINA(A1:A5, 0) = 0
セル範囲 A1:A5 に FALSE、0.2、0.5、0.4、0.8 という値が入力されている場合の計算結果は、次のとおりです。
MINA(A1:A5) = 0
MINA 関数は、MAXA 関数とよく似た関数です。MAXA 関数の使用例も参照してください。
(配列またはセル範囲として指定されたデータの中で、最も頻繁に出現する値 (最頻値) を返します)書式 =MODE(数値1, 数値2, ...)MODE 関数は、MEDIAN 関数と共にデータの全体的な傾向を知るための統計的な手段として利用できます。
解説
数値1, 数値2、... 計算の対象となる最大 30 個までの数値を指定できます。また、半角のカンマ (,) で区切られた数値の代わりに、配列またはセル範囲を指定することもできます。
引数には、数値、数値配列、あるいは数値を含む範囲を参照する名前、またはセル参照を指定します。使用例引数として指定した配列やセル範囲に、文字列、論理値、または空白セルが含まれる場合、これらの値は無視されます。ただし、値が 0 であるセルは、計算の対象となります。
対象となるデータに重複する値が含まれていない場合、エラー値 #N/A が返されます。
最頻値とは、値の集合内に最も頻繁に現れる値のことで、中央値とは値の集合内でちょうど中央にある値のことです。また、平均値とは、各データの値の平均です。これら 3 つの統計値を合わせて評価することによって、データの全体的傾向をより詳細に把握できます。たとえば、テストの点数を集計した結果、対象となるデータが 3 つの点数の範囲に集中している場合を考えてみましょう。データの約半数が低い点数の範囲に集中し、残りの約半数が 2 つの高い点数の範囲に集中している場合、AVERAGE 関数や MEDIAN 関数の戻り値は、実際のデータが比較的少ない中間の値になることがありますが、MODE 関数の戻り値は実際に最も多かった点数を示すことになります。
MODE({5.6,4,4,3,2,4}) = 4
(負の二項分布を返します)書式 =NEGBINOMDIST(失敗数, 成功数, 成功率)NEGBINOMDIST 関数を利用すると、試行の成功率が一定のとき、成功数 で指定した回数の試行が成功する前に、失敗数 で指定した回数の試行が失敗する確率を計算できます。この関数は二項分布を計算する BINOMDIST 関数に類似していますが、試行の成功数が定数で試行回数が変数である点が異なります。さらに、二項分布の場合と同様に、対象となる試行は独立試行であると見なされます。
負の二項分布の例として、特定の資格を持つ人物を 10 人採用する企業があり、応募者がこの資格を持っている確率は 0.3 であることが経験的にわかっている場合、NEGBINOMDIST 関数を使うと、10 人の有資格者を採用するまでに一定の無資格者を面接する確率を計算することができます。
解説
失敗数 試行が失敗する回数を指定します。成功数 分析のしきい値となる、試行が成功する回数を指定します。
成功率 試行が成功する確率を指定します。
失敗数、成功数 に小数点以下の値を指定しても切り捨てられます。使用例引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。
成功率 <= 0、または 成功率 >= 1 である場合、エラー値 #NUM! が返されます。
(失敗数+成功数-1) 0 である場合、エラー値 #NUM! が返されます。
負の二項分布は次のように定義されます。
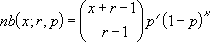
ここでx = 失敗数
r = 成功数
p = 成功率
NEGBINOMDIST(10,5,0.25) = 0.055049
(指定した平均と標準偏差に対する正規分布関数の値を返します)書式 =NORMDIST(x, 平均, 標準偏差, 関数形式)この関数は、仮説検定を始めとする統計学の幅広い分野に応用できます。
解説
x 関数に代入する数値を指定します。平均 分布の算術平均 (相加平均) を指定します。
標準偏差 分布の標準偏差を指定します。
関数形式 計算に使用する関数の種類を、論理値で指定します。関数形式 に TRUE を指定すると累積分布関数の値が計算され、FALSE を指定すると確率密度関数の値が計算されます。
平均、標準偏差 に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例標準偏差 0 の場合、エラー値 #NUM! が返されます。
平均 = 0 かつ 標準偏差 = 1 である場合、標準正規分布関数 (NORMSDIST 関数) の値が計算されます。
正規分布の確率密度関数は次の式で定義されます。
NORMDIST(42,40,1.5,TRUE) = 0.908789
(指定した平均と標準偏差に対する正規累積分布関数の逆関数の値を返します)書式 =NORMINV(確率, 平均, 標準偏差)
解説
確率 正規分布における確率を指定します。平均 分布の算術平均 (相加平均) を指定します。
標準偏差 分布の標準偏差値を指定します。
引数に数値以外の値を指定すると、エラー #VALUE! が返されます。使用例確率 < 0 、または 確率 > 1 である場合、エラー値 #NUM! が返されます。
標準偏差 0 の場合、エラー値 #NUM! が返されます。
平均 = 0 かつ 標準偏差 = 1 である場合、標準正規分布関数 (NORMSDIST 関数) の逆関数の値が返されます。
NORMINV 関数では、関数値の計算に反復計算の手法が利用されます。確率の値が指定されると、計算結果の精度が ±3x10-7 以内になるまで反復計算が行われます。100 回反復計算を繰り返しても計算結果が収束しない場合、エラー値 #N/A が返されます。
NORMINV(0.908789,40,1.5) = 42
(標準正規累積分布関数の値を返します)書式 =NORMSDIST(z)この分布は、平均が 0(ゼロ) で標準偏差が 1 である正規分布に対応します。正規分布表の代わりにこの関数を使用することができます。
解説
z 関数に代入する値を指定します。
z に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例正規分布の標準密度関数は次の式で定義されます。
NORMSDIST(1.333333) = 0.908789
(標準正規累積分布関数の逆関数の値を返します)書式 =NORMSINV(確率)この分布は、平均が 0 で標準偏差が 1 である正規分布に対応します。
解説
確率 正規分布における確率を指定します。
確率 に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例確率 < 0、または 確率 > 1 である場合、エラー値 #NUM! が返されます。
NORMSINV 関数では、関数値の計算に反復計算の手法が利用されます。確率の値が指定されると、計算結果の精度が ±3x10-7 以内になるまで反復計算が行われます。100 回反復計算を繰り返しても計算結果が収束しない場合、エラー値 #N/A が返されます。
NORMSINV(0.908789) = 1.3333
(ピアソンの積率相関係数 r の値を返します)書式 =PEARSON(配列1, 配列2)r は -1.0 から 1.0 の範囲の数値で、2 組のデータ間での線形相関の程度を示します。
解説
配列1 複数の独立変数に対応するデータを指定します。配列2 複数の従属変数に対応するデータを指定します。
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
配列1 と 配列2 にデータが含まれていないとき、または両者のデータの個数が異なるときは、エラー値 #N/A が返されます。
回帰直線の r の値は次のように定義されています。
PEARSON({9,7,5,3,1},{10,6,1,5,3}) = 0.699379
(配列 のデータの中で、百分率で 率 に位置する値を返します)書式 =PERCENTILE(配列, 率)PERCENTILE 関数は入学試験などの合否ラインなどを決めるときに利用します。たとえば、PERSENTILE 関数を使って、成績が上位 10% の志願者を合格とすることができます。
解説
配列 相対的な位置を決定するため、数値データを含む配列またはセル範囲を指定します。率 0 ? 1 の範囲で、目的の百分位の値を指定します。
配列 にデータが含まれていないとき、または 配列 のデータ数が 8,191 個を超えるとき、エラー値 #NUM! が返されます。使用例率 に数値以外の値を指定すると、エラー値 #VALUE! が返されます。
率 < 0 または 率 > 1 の場合、エラー値 #NUM! が返されます。
率 が 1/(データの個数-1) の倍数でない場合、百分位で 率 に位置する値を割り出すため、データの補間が行われます。
PERCENTILE({1,2,3,4},0.3) = 1.9
(配列 に含まれる値の中で、百分率を使った x の順位を返します)書式 =PERCENTRANK(配列, x, 有効桁数)PERCENTRANK 関数は、1 組のデータの中で値の相対的な位置を計算するために利用します。たとえば、あるテストの成績が 70 点である人の相対的な順位を計算するために、PERCENTRANK 関数を使います。
解説
配列 相対的な位置を決定するため、数値データを含む配列またはセル範囲を指定します。x 相対的な順位を調べる値を指定します。
有効桁数 省略可能な引数で、計算結果として返される百分率の有効桁数を指定します。有効桁数 を省略すると、小数点以下第三位 (0.xxx%) まで計算されます。
配列 にデータが含まれていないと、エラー値 #NUM! が返されます。使用例有効桁数 < 1 の場合、エラー値 #NUM! が返されます。
x に相当する値が 配列 に含まれていない場合、正しい順位を計算するため、データの補間が行われます。
PERCENTRANK({1,2,3,4,5,6,7,8,9,10},4) = 0.333
(標本数 個から 抜き取り数 個を選択する場合の順列を返します)書式 =PERMUT(標本数, 抜き取り数)順列とは、順序に着目して選択した対象や事象の組み合わせ数を計算したもので、順序に関係なく計算される組み合わせとは異なります。PERMUT 関数は宝くじなどの当選確率を計算するために利用します。
解説
標本数 対象の総数を整数で指定します。抜き取り数 順列計算のために選択する対象の個数を整数で指定します。
引数に小数点以下の値を指定しても切り捨てられます。使用例標本数、抜き取り数 に数値以外の値を指定すると、エラー値 #VALUE! が返されます。
標本数 0 または 抜き取り数 < 0 の場合、エラー値 #NUM! が返されます。
標本数 < 抜き取り数 である場合、エラー値 #NUM! が返されます。
順列は次の式で計算されます。
宝くじの当選確率を計算するとします。宝くじの番号が 0 (ゼロ) ? 99 の範囲の数を 3 つ並べたものである場合、次の数式によって、組み合わせとして可能な順列の総数が計算できます。PERMUT(100,3) = 970,200
(ポアソン確率分布の値を返します)書式 =POISSON(イベント数, 平均, 関数形式)通常、ポアソン分布は一定の時間内に起きる事象の数を予測するために利用されます。たとえば、ポアソン分布を使って、高速道路の料金所を 1 分間に通過する自動車の台数を予測することができます。
解説
イベント数 生じる事象の数を指定します。平均 一定の時間内に起きる事象の平均値を指定します。
関数形式 確率分布を計算する関数形式を、論理値で指定します。関数形式 に TRUE を指定すると、生起するランダムな事象の数が 0 から イベント数 の範囲であるような累積ポアソン確率分布関数が計算されます。また、関数形式 に FALSE を指定すると、生起する事象の数が正確に イベント数 となるようなポアソン確率密度関数が計算されます。
イベント数 に小数点以下の値を指定しても切り捨てられます。使用例イベント数 または 平均 に数値以外の値を指定すると、エラー値 #VALUE! が返されます。
イベント数 0 の場合、エラー値 #NUM! が返されます。
平均 0 の場合、エラー値 #NUM! が返されます。
POISSON 関数は、次のように計算されます。
関数形式 = FALSE の場合
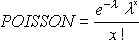
関数形式 =TRUE の場合
POISSON(2,5,FALSE) = 0.084224POISSON(2,5,TRUE) = 0.124652
(x範囲 に含まれる値が 下限 と 上限 との間に収まる確率を返します)書式上限 を省略すると、x範囲 に含まれる値が 下限 と等しくなる確率が計算されます。
PROB(x範囲, 確率範囲, 下限, 上限)解説x範囲 確率範囲 と対応関係にある数値 x を含む配列またはセル範囲を指定します。
確率範囲 x範囲 に含まれるそれぞれの数値に対応する確率を指定します。
下限 対象となる数値の下限を指定します。
上限 省略可能な引数で、対象となる数値の上限を指定します。
確率範囲 に含まれる値が 0 未満または 1 を超えるとき、エラー値 #NUM! が返されます。使用例確率範囲 に含まれる値の合計が 1 にならないとき、エラー値 #NUM! が返されます。
上限 を省略すると、x範囲 に含まれる数値が 下限 の値に等しくなる確率が計算されます。
x範囲 と 確率範囲 のデータの個数が異なると、エラー値 #N/A が返されます。
PROB({0,1,2,3},{0.2,0.3,0.1,0.4},2) = 0.1PROB({0,1,2,3},{0.2,0.3,0.1,0.4},1,3) = 0.8
(配列 に含まれるデータから四分位数を抽出します)書式 =QUARTILE(配列, 戻り値)四分位数は、市場調査などのデータで、母集団を複数のグループに分割するために利用されます。たとえば、QUARTILE 関数を使って、母集団の中から所得金額が全体の上位 25% を占めるグループを選び出すことができます。
配列 対象となる数値データを含む配列またはセル範囲を指定します。解説戻り値 戻り値として返される四分位数の内容を、0 ? 4 までの数値で指定します。
戻り値 QUARTILE 関数の戻り値 0 データの最小値 1 下位 4 分の 1 (25%) 2 データの中央値 (50%) 3 上位 4 分の 1 (75%) 4 データの最大値
配列 にデータが含まれていないとき、または 配列 に 8191 を超えるデータが含まれているとき、エラー値 #NUM! が返されます。使用例戻り値 に小数点以下の値を指定しても切り捨てられます。
戻り値 < 0 または 戻り値 > 4 の場合、エラー値 #NUM! が返されます。
戻り値 に 0、2、4 のいずれかの数値を指定すると、QUARTILE 関数の戻り値は、それぞれ MIN 関数、MEDIAN 関数、MAX 関数の戻り値に等しくなります。
QUARTILE({1,2,4,7,8,9,10,12},1) = 3.5
(順序 に従って 範囲 内の数値を並べ替えたとき、数値 が何番目に位置するかを返します)書式 =RANK(数値, 範囲, 順序)
数値 範囲 内での順位 (位置) を調べる数値を指定します。解説範囲 数値 を含むセル範囲の参照または名前、または数値配列を指定します。範囲 内に含まれている数値だけが計算の対象となり、そこに含まれている文字列、空白セル、論理値は無視されます。また、範囲 内にエラー値が含まれていると、そのエラー値が返されます。
順序 数値 の順位を決めるため、範囲 内の数値を並べ替える方法を指定します。
順序 に 0 を指定するか、または 順序 を省略すると、範囲 内の数値が ...3、2、1 のように降順に並べ替えられます。
順序 に 0 以外の数値を指定すると、範囲 内の数値が 1、2、3、... のように昇順で並べ替えられます。
RANK 関数では、重複した数値は同じ順位と見なされます。数値が重複していると、それ以降の数値の順位がずれていきます。たとえば、整数のリストがあり、そのリストに 10 が 2 度現れ、その順位が 5 であるとき、11 の順位は 7 となります (順位が 6 の数値はありません)。使用例
次の例は、セル範囲 A1:A5 のそれぞれに、数値の 7、3.5、3.5、1、2 が入力されている場合です。RANK(A2,A1:A5,1) = 3
RANK(A1,A1:A5,1) = 5
(既知のy と 既知のx を通過する回帰直線を対象に、r2 の値を返します)書式 =RSQ(既知のy, 既知のx)詳細については、PEARSON 関数を参照してください。r2 の値を計算することにより、x の分散に起因する y の分散の比率を解釈することができます。
解説
既知のy 直線回帰のデータを含む配列またはセル範囲を指定します。既知のx 直線回帰のデータを含む配列またはセル範囲を指定します。
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
既知のy と 既知のx にデータが含まれていないとき、または両者のデータの個数が異なるときは、エラー値 #N/A が返されます。
回帰直線の r の値は次のように定義されます。
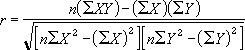
RSQ({2,3,9,1,8,7,5},{6,5,11,7,5,4,4}) = 0.05795
(分布の歪度を返します)書式 =SKEW(数値1, 数値2, ...)歪度とは、分布の平均値周辺での両側の非対称度を表す値です。正の歪度は対称となる分布が正の方向へ伸びる非対称な側を持つことを示し、負の歪度は対称となる分布が負の方向へ伸びる非対称な側を持つことを示します。
数値1, 数値2... 分布の歪度を計算するため、最大 30 個までの数値データを指定します。半角のカンマ (,) で区切られた数値の代わりに、数値配列または数値配列のセル参照を指定することもできます。解説
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
指定する数値データの数が 2 個以下のとき、または標本の標準偏差が 0 (ゼロ) のとき、エラー値 #DIV/0! が返されます。
分布の歪度は次の式で定義されます。
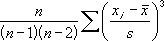
SKEW(3,4,5,2,3,4,5,6,4,7) = 0.359543
(既知のy と 既知のx のデータから回帰直線の傾きを返します)書式 =SLOPE(既知のy, 既知のx)直線の傾きとは、直線上の 2 点の垂直方向の距離を水平方向の距離で除算した値で、回帰直線の変化率に対応します。
解説
既知のy 従属変数の値を含む数値配列またはセル範囲を指定します。既知のx 独立変数の値を含む数値配列またはセル範囲を指定します。
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
既知のy と 既知のx にデータが含まれていないとき、または両者のデータの個数が異なるときは、エラー値 #N/A が返されます。
回帰直線の傾きは次のように定義されます。
SLOPE({2,3,9,1,8,7,5},{6,5,11,7,5,4,4}) = 0.305556
(1 組のデータの中で 順位 番目に小さなデータを返します)書式 =SMALL(範囲, 順位)SMALL 関数を利用すると、相対的な順位に基づいて、データの中から特定の値を選択することができます。
範囲 抽出の対象となるデータが入力されているセル範囲または配列を指定します。解説順位 範囲 で指定したデータから抽出する値の順位 (小さい方から数えた) を数値で指定します。
範囲 にデータが含まれていない場合、エラー値 #NUM! が返されます。使用例順位 0 である場合、または 順位 が対象となるデータの個数よりも大きい場合、エラー値 #NUM! が返されます。
n を 範囲 に含まれているデータの個数とするとき、SMALL(範囲,1) は対象となるデータの中の最小値を返します。また、SMALL(範囲,n) は対象となるデータの中の最大値を返します。
SMALL({3,4,5,2,3,4,5,6,4,7},4) = 4SMALL({1,4,8,3,7,12,54,8,23},2) = 3
(平均 と 標準偏差 で決定される分布を対象に、標準化変量を返します)書式 =STANDARDIZE(x, 平均, 標準偏差)
x 標準化変量を計算する数値を指定します。解説平均 対象となる分布の算術 (相加) 平均を指定します。
標準偏差 対象となる分布の標準偏差を指定します。
標準偏差 0 の場合、エラー値 #NUM! が返されます。使用例標準化変量は次の式で定義されます。
STANDARDIZE(42,40,1.5) = 1.333333
(引数を母集団の標本であると見なして、母集団に対する標準偏差を返します)書式 =STDEV(数値1, 数値2, ...)標準偏差とは、統計的な対象となる値がその平均からどれだけ広い範囲に分布しているかを計量したものです。
数値1, 数値2, ... 母集団の標本に対応する数値を指定します。引数は 1 個から 30 個まで指定できます。数値 はセル範囲に対する参照であってもかまいません。数値 として文字列、論理値、空白セルの参照を指定すると、エラーになります。解説TRUE や FALSE などの論理値、および文字列は無視されます。論理値および文字列を処理する場合は、STDEVA ワークシート関数を使います。
STDEV 関数は、引数を母集団の標本であると見なします。指定する数値が母集団全体である場合は、STDEVP 関数を使って計算します。使用例標準偏差は、非バイアス法または n-1 法を使って計算されます。
STDEV 関数は次の数式を使って標準偏差を計算します。
ある生産ラインで製造された 10 個の部品を対象にして、その強度を測定しました。この値 (1345、1301、1368、1322、1310、1370、1318、1350、1303、1299) がセル範囲 A2:E3 に入力されています。これらの値を母集団の標本と見なして、標準偏差を計算してみましょう。STDEV(A2:E3) = 27.46
(標本に基づいて標準偏差を計算します)書式 =STDEVA(数値1, 数値2,...)標準偏差とは、統計的な対象となる値がその平均 (中数) からどれだけ広い範囲に分布しているかを計量したものです。文字列や、TRUE、FALSE などの論理値も計算の対象となります。
数値1, 数値2,... 母集団の標本に対応する数値を 1 ? 30 個までの範囲で指定します。引数をカンマ (,) で区切って指定する代わりに、配列または配列への参照を使って指定することもできます。解説
STDEVA 関数は、引数を母集団の標本であると見なします。指定する数値が母集団全体である場合は、STDEVPA 関数を使って標準偏差を計算します。使用例引数に TRUE が含まれる場合は 1 と見なされ、文字列または FALSE が含まれる場合は 0 (ゼロ) と見なされます。計算の対象に文字列や論理値を含めない場合は、STDEV ワークシート関数を使用してください。
標準偏差は、非バイアス法または n-1 法を使って計算されます。
STDEVA 関数は次の数式を使って標準偏差を計算します。
ある生産ラインで製造された部品から 10 個を無作為に抽出し、それらを対象にしてその強度を測定しました。この値 (1345、1301、1368、1322、1310、1370、1318、1350、1303、1299) がセル範囲 A2:E3 に入力されています。これらの値を母集団の標本と見なして、標準偏差を計算してみます。STDEV(A2:E3) = 27.46
(引数を母集団全体であると見なして、母集団の標準偏差を返します)書式 =STDEVP(数値1, 数値2, ...)標準偏差とは、統計的な対象となる値が、その平均値からどれだけ広い範囲に分布しているかを計量したものです。
数値1, 数値2, ... 母集団全体に対応する数値を指定します。引数は 1 ? 30 個まで指定できます。数値 はセル範囲に対する参照であってもかまいません。数値 として文字列、論理値、空白セルの参照を指定すると、エラーになります。解説TRUE や FALSE などの論理値、および文字列は無視されます。論理値、および文字列を処理する場合は、STDEVPA ワークシート関数を使います。
STDEVP 関数は、引数を母集団全体であると見なします。指定する数値が母集団の標本である場合は、STDEV 関数を使って計算します。使用例標本数が非常に多い場合、STDEV 関数と STDEVP 関数の戻り値は、ほぼ同じ値になります。
標準偏差は、バイアス法または n 法を使って計算します。
STDEVP 関数は次の数式を使って標準偏差を計算します。
STDEV 関数の使用例と同じデータを使って、それらが母集団全体であると仮定します。製造された部品に対する標準偏差を計算してみましょう。STDEVP(A2:E3) = 26.05
(文字列や論理値を含む引数を母集団全体と見なして、標準偏差を計算します)書式 =STDEVPA(数値1, 数値2,...)標準偏差とは、統計的な対象となる値がその平均 (中数) からどれだけ広い範囲に分布しているかを計量したものです。
数値1, 数値2,... 母集団全体に対応する数値を 1 ? 30 個までの範囲で指定します。引数をカンマ (,) で区切って指定する代わりに、配列または配列への参照を使って指定することもできます。解説
STDEVPA 関数は、引数を母集団全体であると見なします。指定する数値が母集団の標本である場合は、STDEVA 関数を使って標準偏差を計算します。使用例引数に TRUE が含まれる場合は 1 と見なされ、文字列または FALSE が含まれる場合は 0 (ゼロ) と見なされます。計算の対象に文字列や論理値を含めない場合は、STDEVP ワークシート関数を使用してください。
母集団全体の数が非常に多い場合、STDEVA 関数と STDEVPA 関数の戻り値は、ほぼ同じ値になります。
標準偏差は、バイアス法または n 法を使って計算されます。
STDEVPA 関数は次の数式を使って標準偏差を計算します。
STDEVA 関数の使用例と同じデータを使って、それらのデータが母集団全体であると仮定します。STDEVP 関数を使って、部品全体の強度の標準偏差を計算してみます。STDEVP(A2:E3) = 26.05
(回帰直線の標準誤差を返します)書式 =STEYX(既知のy, 既知のx)標準誤差とは、個別の x の値に対する y の予測値の誤差の程度を計測するための尺度です。
既知のy 従属変数の値を含む数値配列またはセル範囲を指定します。解説既知のx 独立変数の値を含む数値配列またはセル範囲を指定します。
引数には、数値、数値配列、または数値を含む範囲を参照する名前かセル参照を指定します。使用例
引数として指定した配列またはセル範囲に、文字列、論理値、または空白セルが含まれている場合、これらは無視されます。ただし、数値として 0 (ゼロ) を含むセルは計算の対象となります。
既知のy と 既知のx にデータが含まれていないとき、または両者のデータの個数が異なるときは、エラー値 #N/A が返されます。
y の予測値の標準誤差は次のように定義されます。
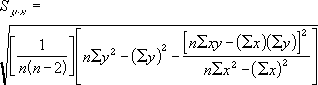
STEYX({2,3,9,1,8,7,5},{6,5,11,7,5,4,4}) = 3.305719
(スチューデントの t 分布のパーセンテージ (確率) を返します)書式 =TDIST(x, 自由度, 尾部)数値 (x) は t の計算値で、この t に対してパーセンテージが計算されます。t 分布は、比較的少数の標本からなるデータを対象に仮説検定を行うときに使われます。この関数は、t 分布表の代わりに使用することができます。
x t 分布を計算する数値を指定します。解説自由度 分布の自由度を整数で指定します。
尾部 片側分布を計算するか両側分布を計算するか、数値で指定します。尾部 に 1 を指定すると片側分布の値が計算され、2 を指定すると両側分布の値が計算されます。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例自由度 < 1 の場合、エラー値 #NUM! が返されます。
自由度、尾部 に小数点以下の値を指定しても切り捨てられます。
尾部 に 1 または 2 以外の数値を指定すると、エラー値 #NUM! が返されます。
TDIST 関数は、TDIST = p(x<X) として計算されます。ここで、X は t 分布に従うランダムな変数です。
TDIST(1.96,60,2) = 0.054645 または 5.46%
(スチューデントの t 分布の t 値を、確率の関数と自由度で返します)書式 =TINV(確率, 自由度)
確率 スチューデントの両側 t 分布に従う確率を指定します。解説自由度 分布の自由度を指定します。
引数に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例確率 < 0 または 確率 > 1 の場合、エラー値 #NUM! が返されます。
自由度 に小数点以下の値を指定しても切り捨てられます。
自由度 < 1 の場合、エラー値 #NUM! が返されます。
TINV 関数は、TINV = p(t<X) として計算されます。ここで、X は t 分布に従うランダムな変数です。
片側 t 値は、確率 に 2* 確率 を指定して返すこともできます。確率 が 0.05、自由度 が 10 の場合、両側値は TINV(0.05,10) で計算され、2.28139 が返されます。同じ 確率 と 自由度 に対する片側値は TINV(2*0.05,10) で計算でき、1.812462 が返されます。
メモ テーブルによっては、確率 が (1-p) として記述されることもあります。TINV 関数では、関数値の計算に反復計算の手法が利用されています。確率の値が指定されると、計算結果の精度が ±3x10-7 以内になるまで反復計算が行われます。100 回反復計算を繰り返しても計算結果が収束しない場合、エラー値 #N/A が返されます。
TINV(0.054645,60) = 1.959997
既知のy と 既知のx のデータを直線に当てはめ (最小二乗法を使って)、その直線上で、指定した 新しいx の配列に対する y の値を近似的に計算します。書式 =TREND(既知のy, 既知のx, 新しいx, 定数)
既知のy 既にわかっている y の値の系列で、y = mx + b という関係になります。解説既知のy の配列が 1 つの列に入力されている場合、既知のx の各列はそれぞれ異なる変数であると見なされます。
既知のy の配列が 1 つの行に入力されている場合、既知のx の各行はそれぞれ異なる変数であると見なされます。
既知のx 既にわかっている x の値の系列で、y = mx + b という関係になります。この引数は省略してもかまいません。既知のx の配列には、1 つまたは複数の変数の系列を指定することができます。変数の系列が 1 つである場合、既知のy と 既知のx は、両者の次元が同じであれば、どのような形の範囲であってもかまいません。変数の系列が複数である場合、既知のy は 1 行または 1 列の範囲でなければなりません。
既知のx を省略すると、既知のy と同じサイズの {1,2,3,...} という配列であると見なされます。
新しいx TREND 関数を利用して、対応する y の値を計算する 新しいx の値を指定します。新しいx には、既知のx と同様、それぞれ独立した変数が入力されている 1 つの列 (または 1 つの行) を指定する必要があります。その結果、既知のy が 1 つの列に入力されている場合、既知のx と 新しいx は同じ列数でなければなりません。また、既知のy が 1 つの行に入力されている場合、既知のx と 新しいx は同じ行数でなければなりません。
新しいx を省略すると、既知のx と同じ値であると見なされます。
既知のx と 新しいx の両方を省略すると、既知のy と同じサイズの {1,2,3,...} という配列であると見なされます。
定数 定数 b を 0 にするかどうかを、論理値で指定します。定数 に TRUE を指定するか省略すると、b の値も計算されます。
定数 に FALSE を指定すると、b の値が 0 (ゼロ) に設定され、y = mx となるように m の値が調整されます。
データを直線に当てはめる方法は、LINEST 関数を参照してください。使用例TREND 関数を利用すると、同じ変数を底とするべき乗を使った多項式曲線による近似計算を行うこともできます。たとえば、A 列に y の値が入力されていて、B 列に x の値が入力されている場合、C 列には x2 の値、D 列には x3 の値を入力し (以下同様)、B 列から D 列 (以下同様) の値を使って、A 列の y の値を近似計算できます。
戻り値が配列となる数式は、配列数式としてセル範囲に入力する必要があります。
既知のx のような引数に対し、配列定数を入力するときは、カンマ (,) を使って同じ行の値を区切り、セミコロン (;) を使って異なる行を区切ります。
過去 1 年間に、ある不動産会社が管理するビル建設用地の価格が堅実な伸びを示しています。このデータを使って、次年度の価格の伸びを予測してみましょう。セル範囲 B2:B13 には、既知のy として、\1,338,900,000、\1,350,000,000、\1,357,900,000、\1,373,000,000、\1,381,300,000、\1,391,000,000、\1,399,000,000、\1,411,200,000、\1,418,900,000、\1,432,300,000、\1,440,000,000、\1,452,900,000 の値が入力されています。
セル範囲 D2:D6 に次の数式が配列数式として入力されている場合、3 月、4 月、5 月、6 月、7 月の価格を予測できます。
TREND(B2:B13,,{13;14;15;16;17}) = {1461715152;1471896970;1482078788;1492260606;1502442424}
計算の結果から、8 月まで待てば、用地を 15 億円以上の価格で販売できることが予測できます。この計算で、既知のx には過去 12 か月を表す既定値の {1;2;3;4;5;6;7;8;9;10;11;12} という配列が使われています。また、{13;14;15;16;17} という配列は、次年度の最初の 5 か月に対応しています。
データ全体の上限と下限から一定の割合のデータを切り落とし、残りの項の平均値を返します。TRIMMEAN 関数は、極端な観察データを分析対象から排除する場合に利用します。書式 =TRIMMEAN(配列, 割合)
配列 対象となるデータを含む配列またはセル範囲を指定します。解説割合 平均値の計算から排除するデータの割合を小数で指定します。たとえば、全体で 20 個のデータを含む対象に対して 割合 に 0.2 を指定した場合、20×0.2 = 4 となり上限から 2 個、下限から 2 個の合計 4 個のデータが排除されることになります。
割合 < 0 または 割合 > 1 の場合、エラー値 #NUM! が返されます。使用例排除されるデータ数が奇数または小数点以下の値を含む場合、切り捨てられて最も近い 2 の倍数 (偶数) にされます。たとえば、データの総数が 30 個で 割合 に 0.1 を指定すると、排除されるデータ数は 30×0.1 = 3 となりますが、実際の計算では、データの上限から 1 個、下限から 1 個の合計 2 個のデータだけが対象から排除されます。
TRIMMEAN({4,5,6,7,2,3,4,5,1,2,3},0.2) = 3.777778
(スチューデントの t 分布に従う確率を返します)書式 =TTEST(配列1, 配列2, 尾部, 検定の種類)TTEST 関数を利用すると、2 つの標本が平均値の等しい母集団から取り出されたものであるかどうかを確率的に予測することができます。
配列1 一方の組のデータを含む配列またはセル範囲を指定します。解説配列2 もう一方の組のデータを含む配列またはセル範囲を指定します。
尾部 片側分布を使用するか、または両側分布を使用するかを数値で指定します。尾部 に 1 を指定すると片側分布が使用され、2 を指定すると両側分布が使用されます。
検定の種類 実行する t 検定の種類を数値で指定します。
検定の種類 働き 1 対をなすデータの t 検定 2 等分散の 2 標本を対象とする t 検定 3 非等分散の 2 標本を対象とする t 検定
配列1 と 配列2 のデータの個数が異なるとき、検定の種類 に 1 を指定すると、エラー値 #N/A が返されます。使用例尾部 と 検定の種類 に小数点以下の値を指定しても切り捨てられます。
尾部 または 検定の種類 に数値以外の値を指定すると、エラー値 #VALUE! が返されます。
尾部 に 1 または 2 以外の数値を指定すると、エラー値 #NUM! が返されます。
TTEST({3,4,5,8,9,1,2,4,5},{6,19,3,2,14,4,5,17,1},2,1) = 0.196016
(引数を母集団の標本であると見なして、母集団に対する分散を返します)書式 =VAR(数値1, 数値2, ...)
数値1, 数値2, ... 母集団の標本に対応する数値を指定します。引数は 1 ? 30 個まで指定できます。数値 にはセル参照に対する参照を指定してもかまいません。数値 として文字列、論理値、空白セルの参照を指定すると、エラーになります。解説
VAR 関数は、引数を母集団の標本であると見なします。指定する数値が母集団全体である場合は、VARP 関数を使って分散を計算します。使用例TRUE や FALSE などの論理値、および文字列は無視されます。論理値、および文字列を処理する場合は、VARA ワークシート関数を使います。
VAR 関数は次の数式を使って分散を計算します。
ある生産ラインで製造された部品から 10 個を無作為に抽出し、それらを対象にしてその強度を測定しました。この値 (1345、1301、1368、1322、1310、1370、1318、1350、1303、1299) がセル範囲 A2:E3 に入力されています。これらの値を母集団の標本と見なして、分散を計算してみましょう。VAR(A2:E3) = 754.2667
(標本に対する分散を計算します)書式 =VARA(数値1, 数値2,...)数値以外に、文字列や、TRUE、FALSE などの論理値も計算の対象となります。
数値1, 数値2,... 母集団の標本に対応する数値を 1 ? 30 個までの範囲で指定します。解説
VARA 関数は、引数を母集団の標本であると見なします。指定する数値が母集団全体である場合は、VARPA 関数を使って分散を計算します。使用例引数に TRUE が含まれている場合は 1 と見なされ、文字列または FALSE が含まれている場合は 0 (ゼロ) と見なされます。計算の対象に文字列または論理値を含めない場合は、VAR ワークシート関数を使用してください。
VARA 関数は次の数式を使って分散を計算します。
ある生産ラインで製造された部品から 10 個を無作為に抽出し、それらを対象にしてその強度を測定しました。この値 (1345、1301、1368、1322、1310、1370、1318、1350、1303、1299) がセル範囲 A2:E3 に入力されています。これらの値を母集団の標本とみなして、分散を計算してみます。VARA(A2:E3) = 754.3
(引数を母集団全体であると仮定して、母集団の分散を返します)書式 =VARP(数値1, 数値2, ...)
数値1, 数値2, ... 母集団全体に対応する数値を指定します。引数は 1 ? 30 個まで指定できます。数値 はセル範囲に対する参照であってもかまいません。数値 として文字列、論理値、空白セルの参照を指定すると、エラーになります。解説TRUE や FALSE などの論理値、および文字列は無視されます。論理値、および文字列を処理する場合は、VARPA ワークシート関数を使います。
VARP 関数は、引数を母集団全体であると見なします。指定する数値が母集団の標本である場合は、VAR 関数を使って分散を計算します。使用例VARP 関数は次の数式を使って分散を計算します。
VAR 関数の使用例と同じデータを使って、それらが母集団全体であると仮定します。製造された部品の分散を計算してみましょう。VARP(A2:E3) = 678.8
(引数を母集団全体と見なして、分散を計算します)書式 =VARPA(数値1, 数値2,...)数値以外に、文字列や、TRUE、FALSE などの論理値も計算の対象となります。
数値1, 数値2,... 母集団全体に対応する数値を 1 ? 30 個までの範囲で指定します。解説
VARPA 関数は、引数を母集団全体であると見なします。指定する数値が母集団の標本である場合は、VARA 関数を使って分散を計算します。使用例引数に TRUE が含まれる場合は 1 と見なされ、文字列または FALSE が含まれる場合は 0 (ゼロ) と見なされます。計算の対象に文字列や論理値を含めない場合は、VARP ワークシート関数を使用してください。
VARPA 関数は次の数式を使って分散を計算します。
VARA 関数の使用例と同じデータを使って、それらのデータが母集団全体であると仮定します。VARPA 関数を使って、部品全体の強度の分散を計算してみます。VARPA(A2:E3) = 678.8
(ワイブル分布の値を返します)この分布は、機械が故障するまでの平均時間のような信頼性の分析に使用されます。
書式 =WEIBULL(x, α, β, 関数形式)
x 関数に代入する数値を指定します。解説α 分布のパラメータを指定します。
β 分布のパラメータを指定します。
関数形式 計算に使用する関数の形式を、論理値で指定します。関数形式 に TRUE を指定すると累積分布関数の値が計算され、FALSE を指定すると確率密度関数の値が計算されます。
x、α、β に数値以外の値を指定すると、エラー値 #VALUE! が返されます。使用例x < 0 の場合、エラー値 #NUM! が返されます。
α 0 または β 0 である場合、エラー値 #NUM! が返されます。
ワイブル累積分布関数は次の式で定義されます。
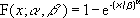
ワイブル確率密度関数は次の式で定義されます。
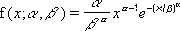
α = 1 の場合、次の式で定義される指数分布関数の値が計算されます。
WEIBULL(105,20,100,TRUE) = 0.929581WEIBULL(105,20,100,FALSE) = 0.035589
(z 検定の両側 P 値を返します)書式 =ZTEST(配列, x, σ)z 検定では、配列 で指定されたデータについて x の標準値が計算され、正規分布に従う両側の確率が計算されます。この関数は、特定の観測値が特定の母集団から得られたということの有意性を検定するために使用します。
配列 x の検定対象となるデータを含む数値配列またはセル範囲を指定します。解説x 検定する値を指定します。
σ 母集団全体に基づく標準偏差を指定します。省略すると、標本に基づく標準偏差が使用されます。
配列 にデータが含まれていない場合、エラー値 #N/A が返されます。使用例ZTEST 関数では次のような計算が行われます。
ZTEST({3,6,7,8,6,5,4,2,1,9},4) = 0.090574